Begin 组件 (Begin Component)
工作流中的起始组件。
Begin (开始) 组件用于设置欢迎语或接收用户输入。无论是通过模板还是从头开始(使用空白模板)创建智能体,该组件都会自动生成在画布上。一个工作流中应该有且仅有一个 Begin 组件。
适用场景 (Scenarios)
Begin 组件在所有情况下都是必不可少的。每个智能体都包含一个 Begin 组件,且该组件无法被删除。
配置项 (Configurations)
点击该组件以显示其 Configuration (配置) 窗口。在这里,您可以设置欢迎语以及智能体的输入参数(全局变量)。
Mode (模式)
模式定义了如何触发工作流。
- Conversational (对话模式):通过对话触发智能体。
- Task (任务模式):在没有对话的情况下直接启动智能体。
- Webhook (网页挂钩模式):通过 Webhook 接收外部 HTTP 请求,从而实现自动触发和工作流启动。
选择此模式后,将为当前智能体生成一个唯一的 Webhook URL。
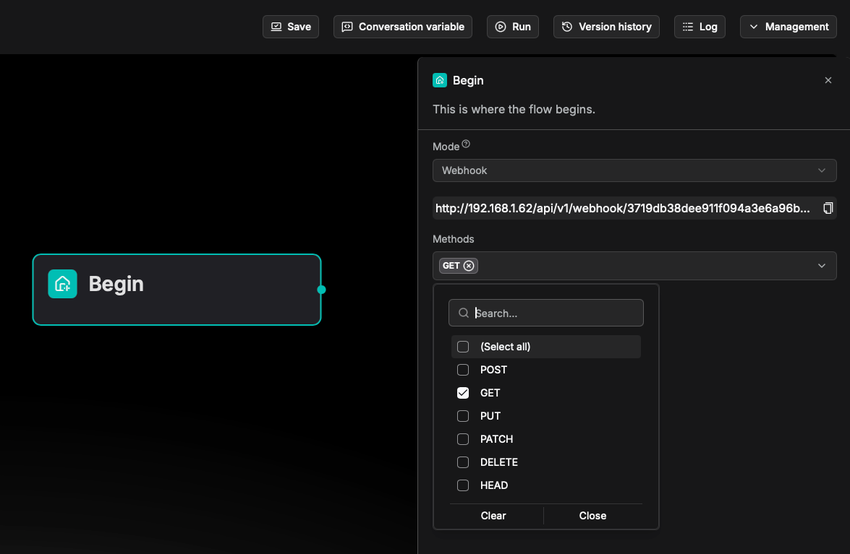
Methods (方法)
支持的 HTTP 方法。仅在 Mode 选择为 Webhook 时可用。
Security (安全性)
选择的认证方法,仅在 Mode 选择为 Webhook 时可用。包括:
- token (令牌):基于 Token 的身份验证。
- basic (基本认证):基于用户名和密码的基本身份验证。
- jwt (JSON Web 令牌):基于 JWT 的身份验证。
Schema (架构)
架构 (Schema) 定义了系统在 Webhook 模式下接收到的 HTTP 请求的数据结构。其配置包括:
- Content type (内容类型):
application/jsonmultipart/form-dataapplication/x-www-form-urlencodedtext-plainapplication/octet-stream
- Query parameters (查询参数)
- Header parameters (标头参数)
- Request body parameters (请求体参数)
Response (响应)
仅在 Mode 选择为 Webhook 时可用。
工作流的响应模式,即工作流如何响应外部 HTTP 请求。支持的选项包括:
- Accepted response (已接受响应):当 HTTP 请求通过验证后,立即返回成功响应,工作流则在后台异步运行。
- 选择此项后,您需要在 Begin 组件中配置相应的 HTTP 状态码和消息。
- 返回的 HTTP 状态码范围为
200-399。
- Final response (最终响应):只有在整个工作流运行完成后,系统才返回最终的处理结果。
- 选择此项后,您需要在 Message 组件 中配置相应的 HTTP 状态码和消息。
- 返回 of HTTP 状态码范围为
200-399。
Opening greeting (欢迎语)
仅限对话模式。
处于对话模式的智能体将以欢迎语开始。这是智能体在对话模式下向用户发送的第一条消息,可以是欢迎词或引导用户进行后续操作的指令。
Global variables (全局变量)
您可以在 Begin 组件中定义全局变量,这些变量可以是必填的或选填的。设置之后,用户在与智能体交互时需要为这些变量提供数值。点击 + Add variable (添加变量) 以添加全局变量,每个变量具有以下属性:
- Name (名称):必填
对该变量的描述性名称,提供更多详细细节。 - Type (类型):必填
该变量的类型:- Single-line text (单行文本):接收不带换行符的单行文本。
- Paragraph text (多行文本):接收多行文本,支持换行符。
- Dropdown options (下拉菜单):要求用户从下拉菜单中为此变量选择一个值。并且您需要为该下拉菜单设置_至少一个_选项。
- file upload (文件上传):要求用户上传一个或多个文件。
- Number (数字):接收数字作为输入。
- Boolean (布尔值):要求用户在开启 (On) 和关闭 (Off) 之间切换。
- Key (键):必填
唯一的变量名。 - Optional (可选的):一个开关,表明该变量是否为选填项。
要从客户端传入参数,请调用:
- HTTP 方法:Converse with agent (与智能体对话),或
- Python 方法:Converse with agent (与智能体对话)。
如果您将键类型设置为 file(文件),请确保上传文件的 token 数量不会超过您的模型提供商的最大 token 限制;否则,文件中的纯文本内容会被截断且不完整。
您可以通过设置环境变量 DOC_BULK_SIZE 和 EMBEDDING_BATCH_SIZE 来调整文档解析和嵌入的效率。
常见问题 (FAQ)
上传的文件会被放入数据集中吗?
不会。作为输入上传到智能体的文件不会存储在数据集中,因此不会使用 RAGFlow 内置的 OCR、DLR 或 TSR 模型进行处理,也不会使用 RAGFlow 内置的分块方法进行分块。
上传文件的大小限制是多少?
对于上传到智能体的文件,没有特定的大小限制。但是请注意,模型提供商通常有默认或明确的最大 token 设置(范围从 8196 到 128k 不等):上传文件的纯文本部分会作为键值传入,但如果该文件的 token 数超过了模型限制,字符串会被截断导致内容不完整。
在 /docker/.env 中的 MAX_CONTENT_LENGTH 变量以及在 /docker/nginx/nginx.conf 中的 client_max_body_size 变量设置了上传到数据集或 RAGFlow 文件系统的文件大小限制。这些设置在此场景中并不适用。