常见问题解答 (FAQs)
有关通用功能、故障排除、用法等问题的解答。
- 通用功能
- RAGFlow 与其他 RAG 产品有什么不同?
- 哪些嵌入模型 (Embedding models) 可以本地部署?
- 在哪里可以找到 RAGFlow 的版本号?如何解读它?
- 为什么不使用其他开源向量数据库作为文档引擎?
- cloud.ragflow.io 与本地部署的开源 RAGFlow 服务有什么区别?
- 为什么 RAGFlow 解析文档的时间比 LangChain 更长?
- 为什么 RAGFlow 相比其他项目需要消耗更多资源?
- RAGFlow 支持哪些架构或设备?
- 你们是否提供可与第三方应用集成的 API?
- 是否支持流式输出 (Stream output)?
- 是否支持通过 URL 分享对话?
- 是否支持多轮对话,即将先前的对话作为当前查询的上下文?
- AI 搜索与 AI 对话的关键区别?
- 故障排除
- 升级至 v0.25.2 时遇到
Request error 404: undefined报错 - 如何从头构建 RAGFlow 镜像?
- 无法访问 https://huggingface.co
- 出现错误
Fail to access model(Ollama/xxxxx) - 出现错误
MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443) - 出现错误
RuntimeError: Unable to start Tika server. - 出现错误
Cannot stat '/etc/nginx/conf.d/ragflow.conf.python': No such file or directory - 出现警告
WARNING: can't find /ragflow/rag/res/borker.tm - 提示
network anomaly There is an abnormality in your network and you cannot connect to the server.(网络异常,无法连接服务器) - 出现警告
Realtime synonym is disabled, since no redis connection - 为什么我的文档解析一直卡在 1% 以下?
- 为什么我的 PDF 解析卡在快要结束的地方,而日志中没有任何报错?
- 出现
Index failure报错 - 如何查看 RAGFlow 的日志?
- 如何检查 RAGFlow 中各组件的状态?
- 出现异常:
Exception: Can't connect to ES cluster - 无法启动 ES 容器,报错
Elasticsearch did not exit normally - 出现错误
{"data":null,"code":100,"message":"<NotFound '404: Not Found'>"} - Ollama Mistral 实例运行在 127.0.0.1:11434,但在 RAGFlow 中添加 Ollama 模型失败
- 你们是否提供使用 DeepDoc 解析 PDF 或其他文件的示例?
- 出现错误
FileNotFoundError: [Errno 2] No such file or directory
- 升级至 v0.25.2 时遇到
- 使用方法
- 如何使用本地部署的大语言模型 (LLM) 运行 RAGFlow?
- 如何添加一个目前不直接支持的大语言模型?
- 如何将 RAGFlow 与 Ollama 集成?
- 如何修改上传文件大小的限制?
- 出现错误
Error: Range of input length should be [1, 30000] - 如何获取 API 密钥以供第三方应用集成?
- 如何升级 RAGFlow?
- 如何将文档引擎切换为 Infinity?
- 上传的文件存储在 RAGFlow 镜像的什么位置?
- 如何调优文档解析和嵌入的批处理大小 (Batch size)?
- 如何加快对话助手的问答响应速度?
- 如何加快智能体 (Agent) 的问答响应速度?
- 如何使用 MinerU 来解析 PDF 文档?
- 如何配置 MinerU 的特定设置?
- 如何将 MinerU 配合 vLLM 服务器用于文档解析?
- 如何使用外部的 Docling Serve 服务器进行文档解析?
- 如何使用 PaddleOCR 进行文档解析?
通用功能
RAGFlow 与其他 RAG 产品有什么不同?
尽管大语言模型(LLM)显著推进了自然语言处理(NLP)技术,但“垃圾输入,垃圾输出(garbage in, garbage out)”的现状并未改变。与其他检索增强生成(RAG)产品相比,RAGFlow 引入了两个独特的功能:
- 细粒度文档解析:文档解析包含图像和表格,并支持您根据需要进行灵活的人工干预。
- 答案可追溯,减少幻觉:RAGFlow 的回复支持查看其背后的引用和参考来源,这让其答案更加值得信赖。
哪些嵌入模型 (Embedding models) 可以本地部署?
从 v0.22.0 版本开始,我们仅提供精简版(slim edition),不再在镜像标签中追加 -slim 后缀。
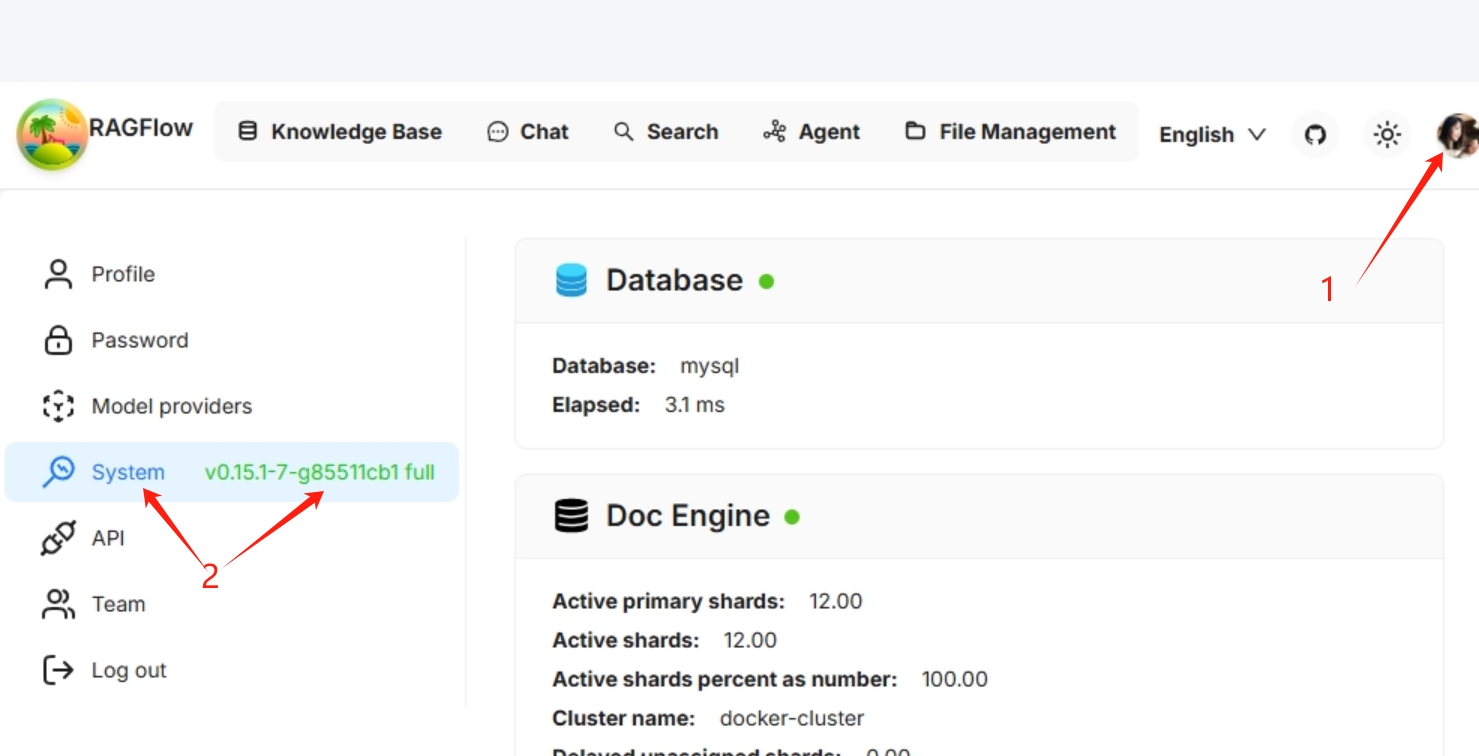
在哪里可以找到 RAGFlow 的版本号?如何解读它?
您可以在用户界面的 System(系统)页面上找到 RAGFlow 的版本号:
如果您是从源码构建 RAGFlow,版本号也可以在系统日志中找到:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
2025-02-18 10:10:43,835 INFO 1445658 RAGFlow version: v0.15.0-50-g6daae7f2
其中:
v0.15.0:官方发布的版本。50:自官方发布以来的 git 提交 (commits) 次数。g6daae7f2:g为前缀,6daae7f2为当前提交 ID (commit ID) 的前七位字符。
为什么不使用其他开源向量数据库作为文档引擎?
目前,只有 Elasticsearch 和 Infinity 能满足 RAGFlow 的混合检索 (Hybrid Search) 需求。大多数开源向量数据库对全文检索的支持非常有限,而且稀疏向量嵌入(sparse embedding)并不能替代全文检索。此外,这些向量数据库缺乏对 RAGFlow 至关重要的关键功能,例如短语搜索和高级排序能力。
正是由于这些局限性,促使我们从零开始开发了 AI 原生数据库 Infinity。
cloud.ragflow.io 与本地部署的开源 RAGFlow 服务有什么区别?
cloud.ragflow.io 展示了 RAGFlow 企业版的能力。其 DeepDoc 模型是使用私有数据预训练的,并且它提供了更复杂的团队权限控制。本质上,cloud.ragflow.io 是 RAGFlow 即将推出的 SaaS(软件即服务)产品的预览。
您可以部署开源的 RAGFlow 服务,并通过 Python 客户端或 RESTful API 进行调用。但这在 cloud.ragflow.io 上是不支持的。
为什么 RAGFlow 解析文档的时间比 LangChain 更长?
我们在文档预处理任务上倾注了大量心血,例如使用我们的视觉模型进行版面分析、表格结构识别和 OCR(光学字符识别)。这正是导致解析耗时增加的原因。
为什么 RAGFlow 相比其他项目需要消耗更多资源?
RAGFlow 内置了多个用于文档结构解析的模型,因此需要消耗更多的计算资源。
RAGFlow 支持哪些架构或设备?
我们官方支持 x86 CPU 和 NVIDIA GPU。虽然我们也在 ARM64 平台上测试 RAGFlow,但我们不维护适用于 ARM 的 RAGFlow Docker 镜像。如果您使用的是 ARM 平台,请参阅此指南来构建 RAGFlow Docker 镜像。
你们是否提供可与第三方应用集成的 API?
相应的 API 现已提供。欲了解更多信息,请参阅 RAGFlow HTTP API 参考 或 RAGFlow Python API 参考。
是否支持流式输出 (Stream output)?
支持。在对话助手(Chat assistant)和智能体(Agent)中,流式输出默认是启用的。请注意,您无法通过 RAGFlow 的 UI 禁用流式输出。若要禁用流式响应,请使用 RAGFlow 的 Python 或 RESTful API:
Python:
RESTful:
是否支持通过 URL 分享对话?
目前不支持此功能。
是否支持多轮对话,即将先前的对话作为当前查询的上下文?
支持,我们支持根据正在进行的对话上下文来优化和增强用户的查询:
- 在 Chat(对话)页面上,将鼠标悬停在所需的助手上并选择 Edit(编辑)。
- 在弹出菜单的 Chat Configuration(对话配置)中,点击 Prompt engine(提示词引擎)标签页。
- 开启 Multi-turn optimization(多轮优化)来启用该功能。
AI 搜索与 AI 对话的关键区别?
- AI 搜索:这是一种单轮 AI 对话,采用预定义的检索策略(加权关键词相似度与加权向量相似度的混合检索)以及系统的默认对话模型。它不涉及知识图谱 (Knowledge graph)、自动关键词 (Auto-keyword) 或自动问题 (Auto-question) 等高级 RAG 策略。检索到的分块 (Chunks) 将会列在对话模型回复的下方。
- AI 对话:这是一种多轮 AI 对话,您可以自定义检索策略(例如,可以使用加权重排分数来替代混合检索中的加权向量相似度),并选择您的对话模型。在 AI 对话中,您可以针对您的具体场景配置高级 RAG 策略(如知识图谱、自动关键词和自动问题)。检索到的分块默认不会显示在答案下方。
当调试您的对话助手时,您可以将 AI 搜索作为参考,以验证您的模型设置和检索策略。
故障排除
升级至 v0.25.2 时遇到 Request error 404: undefined 报错
要解决此问题,请采用以下任一方法:
- 从 main 分支拉取最新的源码,然后拉取并启动 v0.25.2 镜像。
- 将 .env 文件中的
RAGFLOW_IMAGE从infiniflow/ragflow:latest更新为infiniflow/ragflow:v0.25.2,然后重启服务。
如何从头构建 RAGFlow 镜像?
无法访问 https://huggingface.co
默认情况下,本地部署 of RAGFlow 会从 Hugging Face 网站 下载 OCR 模型。如果您的机器无法访问该网站,将出现以下错误且 PDF 解析会失败:
FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/hub/models--InfiniFlow--deepdoc/snapshots/be0c1e50eef6047b412d1800aa89aba4d275f997/ocr.res'
要解决此问题,请改用镜像源 https://hf-mirror.com:
-
停止所有容器并删除相关资源:
cd ragflow/docker/
docker compose down -
取消注释 ragflow/docker/.env 中的以下行:
# HF_ENDPOINT=https://hf-mirror.com -
重新启动服务器:
docker compose up -d
出现错误 Fail to access model(Ollama/xxxxx)
由于内存限制或内存溢出 (OOM),Ollama 在首次加载模型时可能会超时或失败。建议先隔离测试您的本地模型。如果与其他服务共享硬件,很容易发生内存耗尽的情况。要解决此问题,请切换至更小的模型或增加物理内存。
出现错误 MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)
该错误提示您没有外网连接能力,或无法连接至 hf-mirror.com。可以尝试以下步骤:
-
手动从 huggingface.co/InfiniFlow/deepdoc 下载资源文件到您的本地文件夹 ~/deepdoc。
-
在 docker-compose.yml 中添加数据卷挂载,例如:
- ~/deepdoc:/ragflow/rag/res/deepdoc
出现错误 RuntimeError: Unable to start Tika server.
该错误几乎总是由于环境中未安装 Java 或 Java 路径无法访问所致。具体解决步骤请参阅此处。
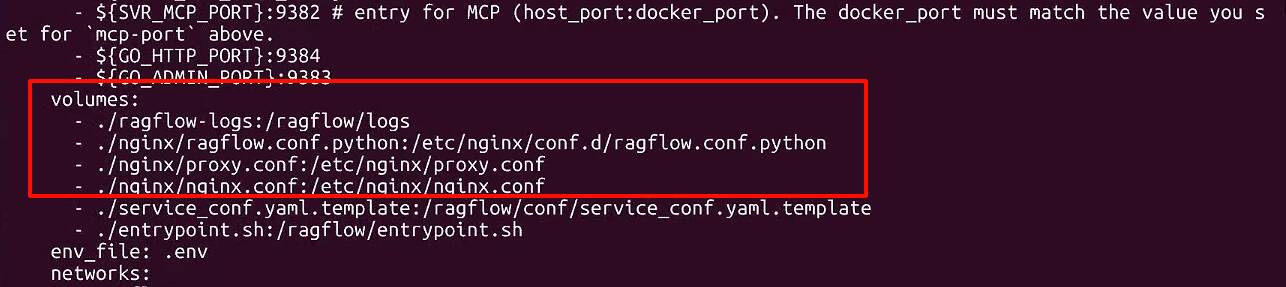
出现错误 Cannot stat '/etc/nginx/conf.d/ragflow.conf.python': No such file or directory
要解决此问题,可以从 GitHub 上的对应版本标签中下载缺失的文件,或者按如下方式更新 ~/ragflow/docker/docker-compose.yml:
出现警告 WARNING: can't find /ragflow/rag/res/borker.tm
请忽略此警告并继续。所有的系统警告都可以被安全忽略。
提示 network anomaly There is an abnormality in your network and you cannot connect to the server.(网络异常,无法连接服务器)
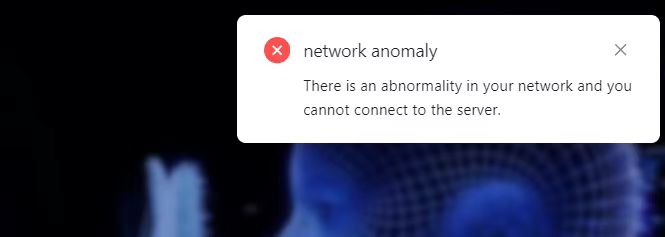
在服务器完全初始化之前,您是无法登录 RAGFlow 的。请运行命令 docker logs -f docker-ragflow-cpu-1 查看日志。
如果您的系统显示以下内容,则表示服务器已成功初始化:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
//_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
出现警告 Realtime synonym is disabled, since no redis connection
请忽略该警告并继续。所有的系统警告均可被安全忽略。

为什么我的文档解析一直卡在 1% 以下?
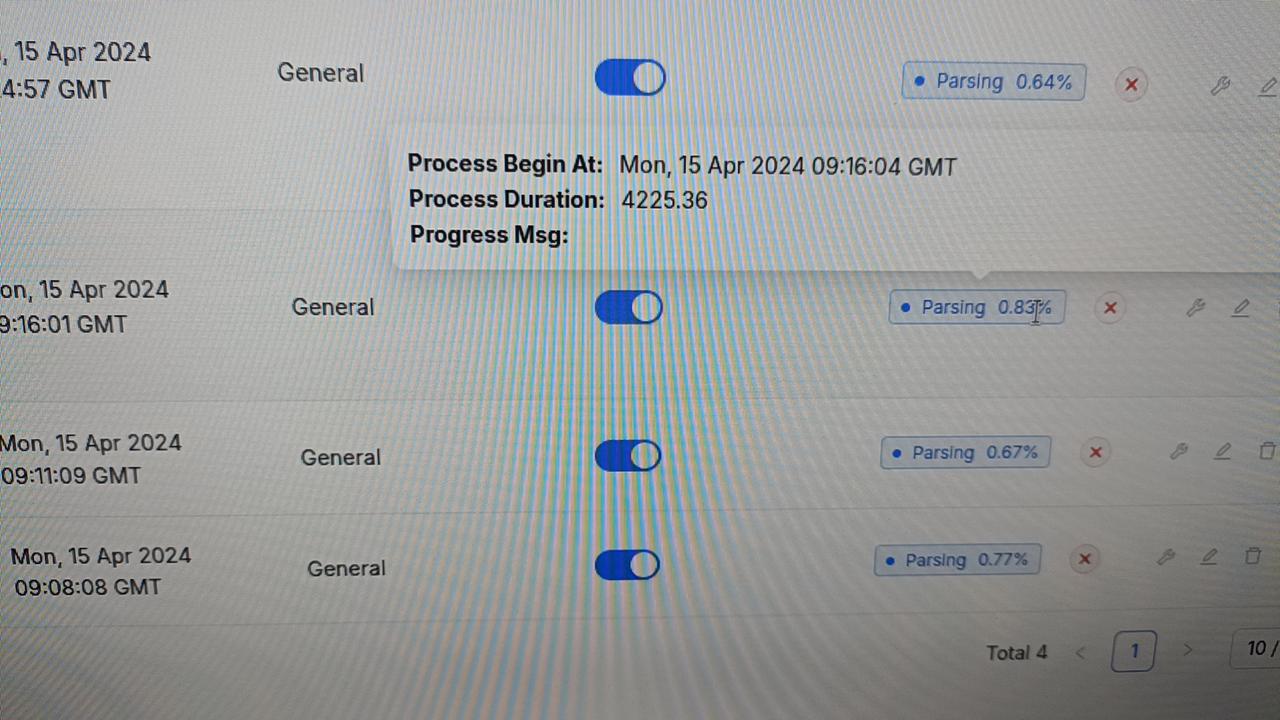
点击“解析状态”栏旁边的红叉停止任务,然后重新启动解析过程,看看问题是否依然存在。如果问题依旧,并且您的 RAGFlow 是本地部署的,请尝试以下步骤:
-
检查您的 RAGFlow 服务器日志,确认其是否正常运行:
docker logs -f docker-ragflow-cpu-1 -
检查 task_executor.py 进程是否存在。
-
检查您的 RAGFlow 服务器是否能访问 hf-mirror.com 或 huggingface.com。
为什么我的 PDF 解析卡在快要结束的地方,而日志中没有任何报错?
点击“解析状态”栏旁边的红叉,重新启动解析过程看问题是否仍存在。如果问题依旧,并且您的 RAGFlow 是本地部署的,这很可能是因为内存 (RAM) 不足导致解析进程被系统终止。可以尝试通过增加 docker/.env 中的 MEM_LIMIT 值来提升内存配额。
确保重新启动您的 RAGFlow 服务器以使修改生效!
docker compose stop
docker compose up -d
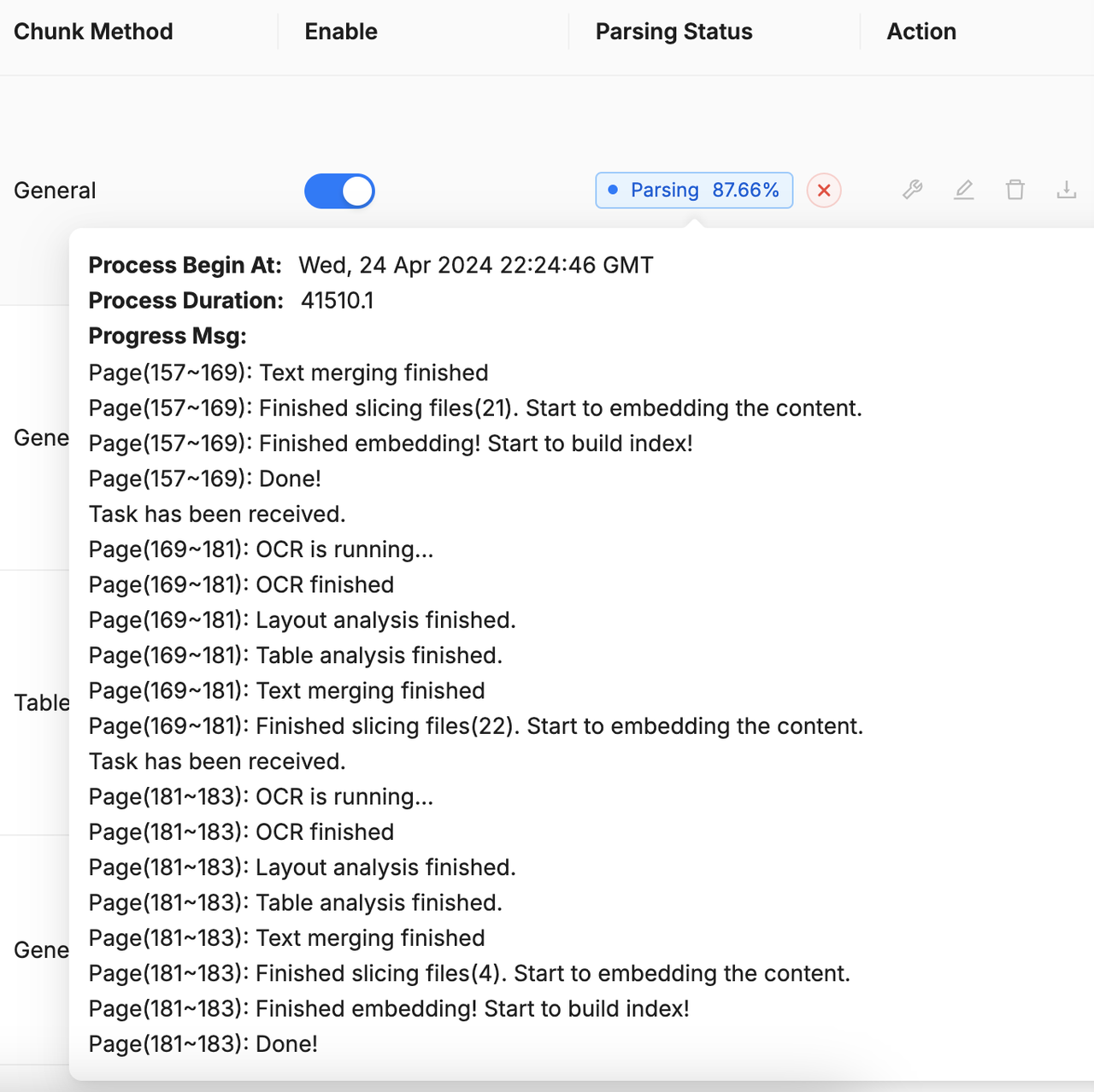
出现 Index failure 报错
索引失败(Index failure)通常表示 Elasticsearch 服务当前不可用。
如何查看 RAGFlow 的日志?
使用以下命令:
tail -f ragflow/docker/ragflow-logs/*.log
如何检查 RAGFlow 中各组件的状态?
-
检查 Elasticsearch Docker 容器的状态:
$ docker ps以下是一个输出结果示例:
5bc45806b680 infiniflow/ragflow:latest "./entrypoint.sh" 11 hours ago Up 11 hours 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp, 0.0.0.0:9380->9380/tcp, :::9380->9380/tcp docker-ragflow-cpu-1
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
d8c86f06c56b mysql:5.7.18 "docker-entrypoint.s…" 7 days ago Up 16 seconds (healthy) 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp ragflow-mysql
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio -
参考此文档来检查 Elasticsearch 服务的运行状况健康度。
Docker 容器的运行状态并不一定反映服务的真实状态。您可能会发现,即使对应的 Docker 容器显示在运行,系统服务实际上也可能处于不健康状态。这可能由网络故障、错误的端口号配置或 DNS 解析问题等引起。
出现异常:Exception: Can't connect to ES cluster
-
检查 Elasticsearch Docker 容器的状态:
$ docker ps一个健康的 Elasticsearch 组件状态应该类似于:
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01 -
参照此文档检查 Elasticsearch 服务的健康状态。
重要提示Docker 容器的状态不一定反映其内服务的实际健康状态。即使 Docker 容器处于 Up 状态,服务也可能无法正常响应。可能的原因包括网络中断、不正确的映射端口或 DNS 设置问题。
-
如果您的容器一直处于不断重启的状态,请按照 此自述文件 / README 中的指示确保
vm.max_map_count≥ 262144。如果您希望更改永久生效,需要更新 /etc/sysctl.conf 文件中的vm.max_map_count属性。注意此配置只适用于 Linux 平台。
无法启动 ES 容器,报错 Elasticsearch did not exit normally
这是因为您忘记在 /etc/sysctl.conf 中更新 vm.max_map_count 的配置,在系统重启后,该属性的值被重置为默认值。
出现错误 {"data":null,"code":100,"message":"<NotFound '404: Not Found'>"}
您的 IP 地址或端口号可能不正确。如果您使用的是默认配置,请直接在浏览器中输入 http://<IP_OF_YOUR_MACHINE>(不要填写 9380,也不需要填写任何端口号!),系统即可以正常打开。
Ollama Mistral 实例运行在 127.0.0.1:11434,但在 RAGFlow 中添加 Ollama 模型失败
正确的 Ollama IP 地址和端口对于在 Ollama 中添加模型至关重要:
- 如果您是在使用 cloud.ragflow.io,请确保托管 Ollama 的服务器拥有公网可访问的 IP 地址。请注意,127.0.0.1 并非公网可访问的 IP。
- 如果您是在本地部署 RAGFlow,请确保 Ollama 和 RAGFlow 处于同一局域网 (LAN) 内且两者可互相通信。
欲了解更多信息,请参阅部署本地大语言模型 (Deploy a local LLM)。
你们是否提供使用 DeepDoc 解析 PDF 或其他文件的示例?
有的。可以查看 rag/app 文件夹下的 Python 文件。
出现错误 FileNotFoundError: [Errno 2] No such file or directory
-
检查 MinIO Docker 容器的状态:
$ docker ps一个健康的 MinIO 容器状态应如下所示:
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio -
参考此文档来检查 Elasticsearch 服务的运行健康度状况。
Docker 容器的 Up 状态并不能完全代表其服务的健康状况。在网络中断、端口配置错误或域名解析失败时,即使容器正在运行,其服务也极可能不可用。
使用方法
如何使用本地部署的大语言模型 (LLM) 运行 RAGFlow?
您可以使用 Ollama 或 Xinference 来部署本地大语言模型。详情请参阅此处。
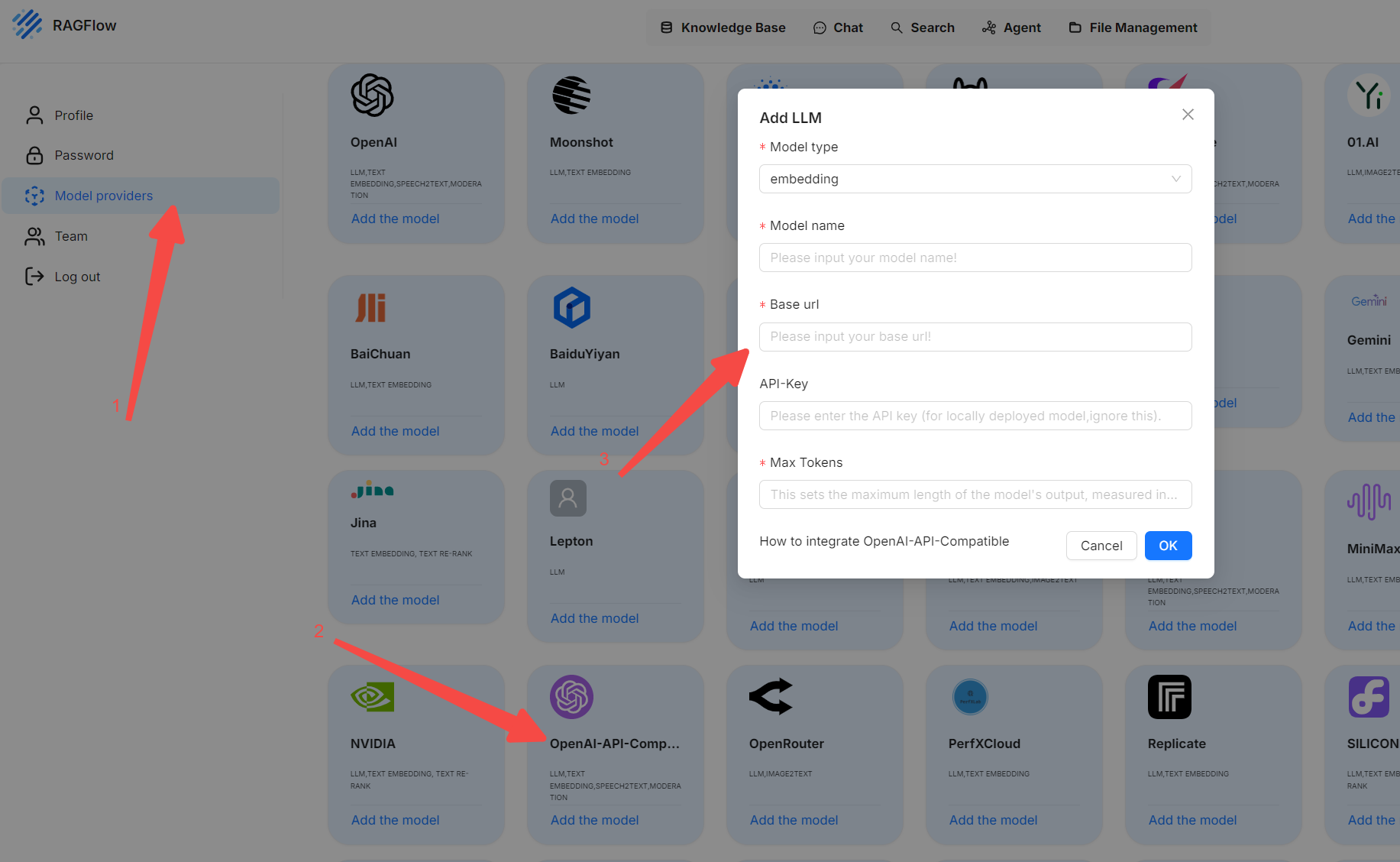
如何添加一个目前不直接支持的大语言模型?
如果您的大语言模型目前不在原生支持列表中,但其 API 与 OpenAI 兼容,可以点击 Model providers(模型提供商)页面上的 OpenAI-API-Compatible(兼容 OpenAI API 的模型)来配置您的模型:
如何将 RAGFlow 与 Ollama 集成?
- 如果 RAGFlow 是本地部署的,请确保您的 RAGFlow 和 Ollama 处于同一个局域网 (LAN) 内。
- 如果您是在使用我们的线上 Demo,请确保您的 Ollama 服务器 IP 是公网公开且可访问的。
详情请参阅此处。
如何修改上传文件大小的限制?
对于本地部署的 RAGFlow:每次上传的总文件大小限制为 1GB,单次批量上传最多支持 32 个文件。每个账户的总文件数量没有限制。要修改这 1GB 的大小限制:
- 在 docker/.env 中,取消对
# MAX_CONTENT_LENGTH=1073741824的注释,并根据需要修改该值(1073741824字节表示 1GB)。 - 如果修改了 docker/.env 中的
MAX_CONTENT_LENGTH值,请确保相应地更新 nginx/nginx.conf 中的client_max_body_size值。
不建议手动更改 32 个文件的单次批量上传限制。不过,如果您是使用 RAGFlow 的 HTTP API 或 Python SDK 批量上传文件,该限制会自动解除。
出现错误 Error: Range of input length should be [1, 30000]
发生此错误是由于匹配搜索条件的文本块 (Chunks) 数量过多。可以通过减少 TopN 以及提高 Similarity threshold(相似度阈值)来解决此问题:
- 点击页面中上方的 Chat(对话)标签页。
- 右键点击目标对话 > Edit(编辑) > Prompt engine(提示词引擎)。
- 降低 TopN 和/或调高 Similarity threshold。
- 点击 OK 确认更改。
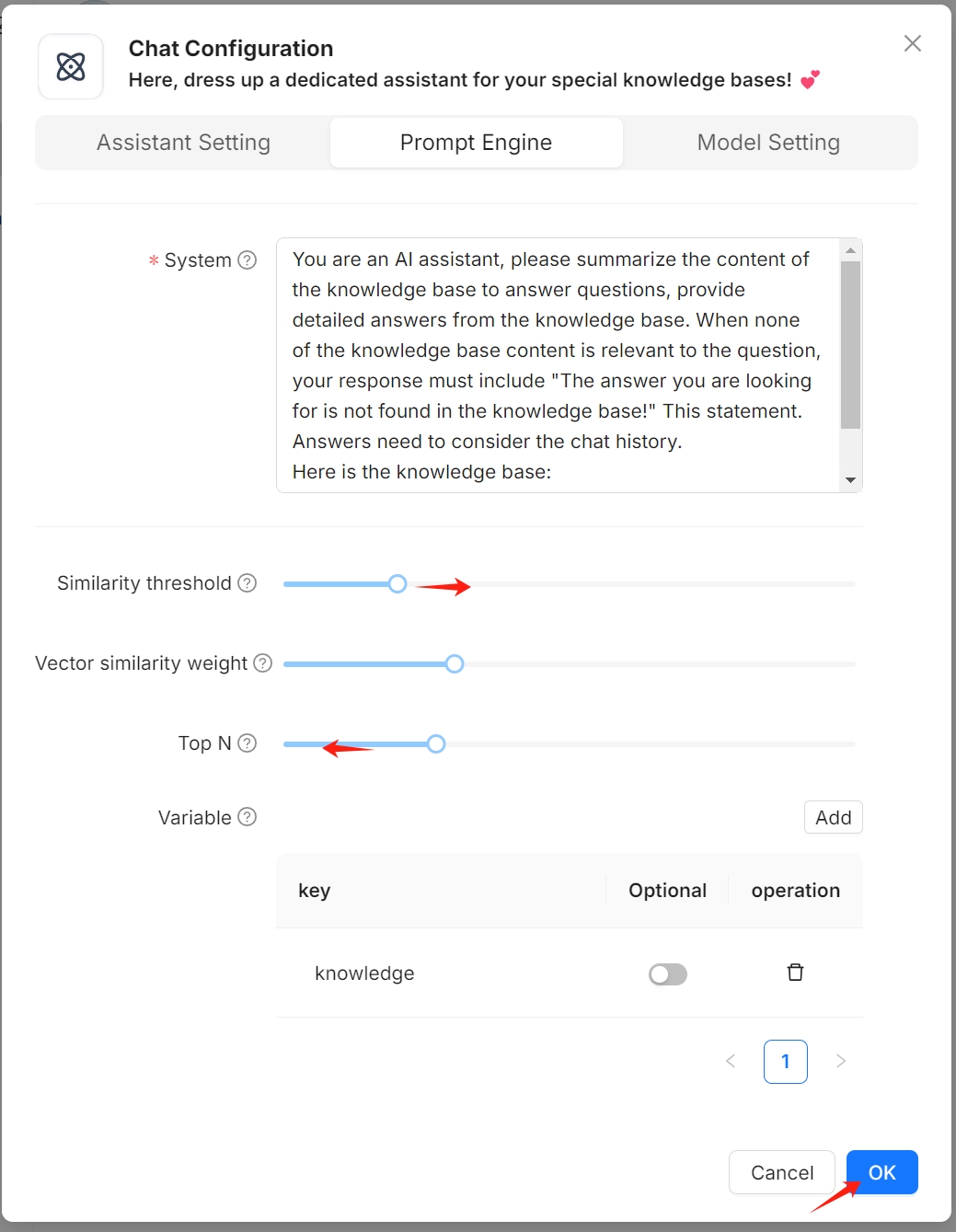
如何获取 API 密钥以供第三方应用集成?
如何升级 RAGFlow?
详情请参阅升级 RAGFlow。
如何将文档引擎切换为 Infinity?
若要将文档引擎从 Elasticsearch 切换至 Infinity:
-
停止所有正在运行的容器:
$ docker compose -f docker/docker-compose.yml down -v警告使用
-v参数会删除所有 Docker 容器卷 (Volumes),已有的数据将会被完全清除! -
在 docker/.env 中,设置
DOC_ENGINE=${DOC_ENGINE:-infinity}。 -
重新启动 Docker 镜像:
$ docker compose -f docker-compose.yml up -d
上传的文件存储在 RAGFlow 镜像的什么位置?
所有上传的文件都存储在 MinIO 中(RAGFlow 的对象存储解决方案)。例如,如果您直接将文件上传到特定的知识库/数据集,它会被保存在 <knowledgebase_id>/filename 路径下。
如何调优文档解析和嵌入的批处理大小 (Batch size)?
您可以通过设置环境变量 DOC_BULK_SIZE 和 EMBEDDING_BATCH_SIZE 来控制文档解析与嵌入的批处理大小。增加这些值可以提高大规模数据处理的吞吐量,本同时也会增加内存开销。请根据您的硬件资源进行调整。
如何加快对话助手的问答响应速度?
请参阅此处。
如何加快智能体 (Agent) 的问答响应速度?
请参阅此处。
如何使用 MinerU 来解析 PDF 文档?
自 v0.22.0 起,RAGFlow 引入了 MinerU (≥ 2.6.3) 作为支持多后端的可选 PDF 解析器 (Parser)。请注意,RAGFlow 仅充当 MinerU 的远程客户端,通过调用 MinerU API 来解析 PDF 并读取返回的文件。要启用此功能:
- 准备一个可达的 MinerU API 服务(FastAPI 服务)。
- 在 .env 文件中,或从界面的 Model providers(模型提供商)页面配置 RAGFlow 的 MinerU 远程客户端:
MINERU_APISERVER:MinerU 的 API 端点(例如,http://mineru-host:8886)。MINERU_BACKEND:MinerU 的后端类型:"pipeline"(默认)"vlm-http-client""vlm-transformers""vlm-vllm-engine""vlm-mlx-engine""vlm-vllm-async-engine""vlm-lmdeploy-engine"
MINERU_SERVER_URL:(可选)下游 vLLM HTTP 服务器(例如,http://vllm-host:30000)。当MINERU_BACKEND设置为"vlm-http-client"时生效。MINERU_OUTPUT_DIR:(可选)用于存放 MinerU API 服务解析完(zip/JSON)提取到本地的文件目录。MINERU_DELETE_OUTPUT:使用临时目录时是否删除临时输出:1:删除。0:保留。
- 在 Web UI 中,导航至您知识库的 Configuration(配置)页面,并找到 Ingestion pipeline(解析流水线)部分:
- 如果您选用的是 Built-in(内置)下拉菜单中的分块方法,请确保其支持 PDF 解析,然后在 PDF parser(PDF 解析器)下拉菜单中选择 MinerU。
- 如果您使用的是自定义解析流水线,请在 Parser(解析器)组件的 PDF parser 区域中选择 MinerU。
所有 MinerU 相关的环境变量都是可选的。设置这些值后,系统会在首次使用时为该租户自动配置 MinerU OCR 模型。如果您想避免自动配置,可以跳过环境变量의 设置,仅在界面的 Model providers 页面配置 MinerU。
第三方视觉模型仍被标记为实验性(Experimental),因为我们尚未针对上述数据提取任务对这些模型进行全面测试。
如何配置 MinerU 的特定设置?
下表汇总了远程 MinerU 最常用的环境变量:
| 环境变量 | 描述 | 默认值 | 示例 |
|---|---|---|---|
MINERU_APISERVER | MinerU API 服务 URL | 未设置 | MINERU_APISERVER=http://your-mineru-server:8886 |
MINERU_BACKEND | MinerU 解析后端 | pipeline | MINERU_BACKEND=pipeline|vlm-transformers|vlm-vllm-engine|vlm-mlx-engine|vlm-vllm-async-engine|vlm-http-client |
MINERU_SERVER_URL | 远程 vLLM 服务器 URL(用于 vlm-http-client) | 未设置 | MINERU_SERVER_URL=http://your-vllm-server-ip:30000 |
MINERU_OUTPUT_DIR | 存放 MinerU 输出文件的目录 | 系统定义的临时目录 | MINERU_OUTPUT_DIR=/home/ragflow/mineru/output |
MINERU_DELETE_OUTPUT | 使用临时目录时是否删除 MinerU 的输出目录 | 1 (删除临时输出) | MINERU_DELETE_OUTPUT=0 |
- 设置
MINERU_APISERVER将 RAGFlow 指向您的 MinerU API 服务器。 - 设置
MINERU_BACKEND指定解析后端。 - 如果使用
"vlm-http-client"后端,将MINERU_SERVER_URL设置为您的 vLLM 服务器 URL。MinerU API 需要在请求体中接收backend=vlm-http-client和server_url=http://<server>:30000。 - 设置
MINERU_OUTPUT_DIR指定 RAGFlow 存储 MinerU API 输出的目录;否则会使用系统临时目录。 - 将
MINERU_DELETE_OUTPUT设置为0可以保留 MinerU 的临时输出(这非常适用于调试)。
有关 MinerU 原生支持的其他环境变量的信息,请参阅此处。
如何将 MinerU 配合 vLLM 服务器用于文档解析?
RAGFlow 支持 MinerU 的 vlm-http-client 后端,这使您能够将文档解析任务委托给远程 vLLM 服务器,同时通过 HTTP 调用 MinerU。配置步骤如下:
- 确保可成功访问 MinerU API 服务(例如
http://mineru-host:8886)。 - 搭建或指向一个 vLLM HTTP 服务器(例如
http://vllm-host:30000)。 - 在您的 docker/.env 文件(若从源码运行,则在命令行环境)中配置以下内容:
MINERU_APISERVER=http://mineru-host:8886MINERU_BACKEND="vlm-http-client"MINERU_SERVER_URL="http://vllm-host:30000"MinerU API 调用将会在请求体中附带backend=vlm-http-client与server_url=http://<server>:30000。
- 根据需要配置
MINERU_OUTPUT_DIR/MINERU_DELETE_OUTPUT来管理导入前的返回 zip/JSON 包。
当使用 vlm-http-client 后端时,RAGFlow 服务器本身不需要 GPU,仅需 network 连通。这使得分布式部署更加具有性价比,多个 RAGFlow 实例可以共享同一个远程 vLLM 服务器。
如何使用外部的 Docling Serve 服务器进行文档解析?
RAGFlow 支持两种 Docling 运行模式:
- 本地 Docling(现有模式):在 RAGFlow 运行时中安装 Docling (
USE_DOCLING=true) 并在进程内执行解析。 - 外部 Docling Serve(远程模式):将 RAGFlow 指向 Docling Serve 端点。
要启用远程模式,请设置:
DOCLING_SERVER_URL=http://your-docling-serve-host:5001
运行逻辑:
- 当设置了
DOCLING_SERVER_URL时,RAGFlow 会使用/v1/convert/source将 PDF 发送到 Docling Serve(对于较旧的服务器,会自动降级使用/v1alpha/convert/source)。 - 若未设置
DOCLING_SERVER_URL,RAGFlow 会默认使用本地进程内的 Docling。
如何使用 PaddleOCR 进行文档解析?
自 v0.24.0 起,RAGFlow 引入了 PaddleOCR 作为可选的 PDF 解析器。请注意,RAGFlow 仅作为 PaddleOCR 的远程客户端,通过调用 PaddleOCR API 解析 PDF 并读取返回的文件。
在 RAGFlow 中,有两种主要配置和使用 PaddleOCR 的方法:
1. 使用 PaddleOCR 官方 API
此方法配合 Access Token 使用 PaddleOCR 的官方 API 服务。
第一步:配置 RAGFlow
-
通过环境变量:
# 在您的 docker/.env 文件中:
PADDLEOCR_API_URL=https://your-paddleocr-api-endpoint
PADDLEOCR_ALGORITHM=PaddleOCR-VL
PADDLEOCR_ACCESS_TOKEN=your-access-token-here -
通过 UI 界面:
- 导航至 Model providers 页面
- 添加一个 Factory 厂商类型为 "PaddleOCR" 的新 OCR 模型
- 配置以下字段:
- PaddleOCR API URL:您的 PaddleOCR API 端点
- PaddleOCR Algorithm:选择对应 API 端点的算法
- AI Studio Access Token:您的 PaddleOCR API 访问令牌 (Access Token)
第二步:在知识库配置中使用
- 在您知识库的 Configuration(配置)页面中,找到 Ingestion pipeline(解析流水线)部分。
- 如果使用的是内置的且支持 PDF 解析的分块方法,请在 PDF parser 下拉菜单中选择 PaddleOCR。
- 如果使用的是自定义解析流水线,请在 Parser 组件中选择 PaddleOCR。
说明:
- 要获取 API 链接,请访问 PaddleOCR 官方网站,点击 API 按钮,选择您要使用的特定算法示例代码(例如 PaddleOCR-VL),然后复制
API_URL。 - Access Token 可以从 AI Studio 平台 获取。
- 此方法需要网络连接才能访问官方 PaddleOCR API。
2. 使用私有化部署的 PaddleOCR 服务
此方法允许您部署自己的 PaddleOCR 服务,无需 Access Token 即可使用。
第一步:部署 PaddleOCR 服务 按照 PaddleOCR 服务化部署文档 部署您自己的服务。对于版面解析,您可以使用类似的端点:
http://localhost:8080/layout-parsing
第二步:配置 RAGFlow
-
通过环境变量:
PADDLEOCR_API_URL=http://localhost:8080/layout-parsing
PADDLEOCR_ALGORITHM=PaddleOCR-VL
# 私有化部署服务无需 Access Token -
通过 UI 界面:
- 导航至 Model providers 页面
- 添加一个 Factory 厂商类型为 "PaddleOCR" 的新 OCR 模型
-配置以下字段:
- PaddleOCR API URL:您部署的服务的端点
- PaddleOCR Algorithm:选择对应所部署服务的算法
- AI Studio Access Token:留空即可
第三步:在知识库配置中使用
- 在您知识库的 Configuration 页面中,找到 Ingestion pipeline 部分。
- 如果使用的是内置的且支持 PDF 解析的分块方法,请在 PDF parser 下拉菜单中选择 PaddleOCR。
- 如果使用的是自定义解析流水线,请在 Parser 组件中选择 PaddleOCR。
环境变量汇总
| 环境变量 | 描述 | 默认值 | 是否必填 |
|---|---|---|---|
PADDLEOCR_API_URL | PaddleOCR API 端点 URL | "" | 是,在使用环境变量时必填 |
PADDLEOCR_ALGORITHM | 用于解析的算法 | "PaddleOCR-VL" | 否 |
PADDLEOCR_ACCESS_TOKEN | 官方 API 的访问令牌 | None | 仅在使用官方 API 时必填 |
环境变量可以用于自动配置,但如果通过 UI 页面进行配置,则不是必需的。当设置了环境变量后,系统会在首次使用时为该租户自动配置 PaddleOCR 模型。