加速回答 (Accelerate Answering)
加速聊天助手问答响应的清单。
请注意,某些设置可能会消耗大量时间。如果您经常发现问答响应较慢,可以对照以下清单进行排查:
- 禁用多轮优化 (Multi-turn optimization) 将减少从大语言模型 (Large Language Model, LLM) 获取回答所需的时间。
- 将**重排模型 (Rerank model)**字段留空将显著减少检索时间。
- 禁用**推理 (Reasoning)**开关将减少 LLM 的思考时间。对于像 Qwen3 这样的模型,您还需要在系统提示词中添加
/no_think以禁用推理。 - 使用重排模型时,请确保有 GPU 用于加速;否则,重排过程将会极其缓慢。
提示
请注意,重排模型在某些场景下是必不可少的。速度与性能之间总是需要权衡,您必须针对具体用例权衡利弊。
- 禁用关键词分析 (Keyword analysis) 将减少接收 LLM 回答的时间。
- 与聊天助手对话时,点击当前对话上方的灯泡图标,并向下滚动弹出窗口,即可查看每个任务所花费的时间:
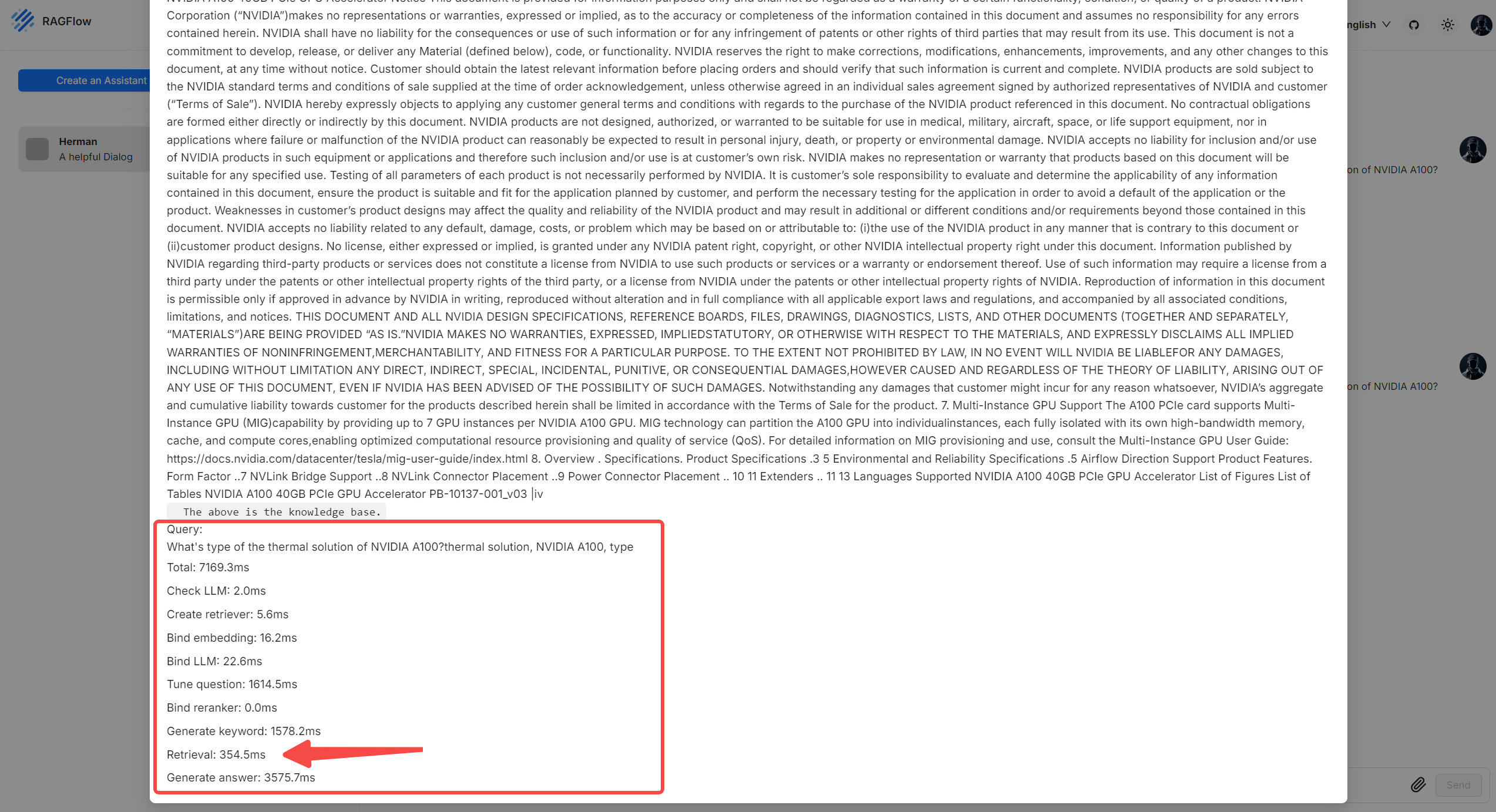
| 项名称 (Item name) | 描述 (Description) |
|---|---|
| 总计 (Total) | 本轮对话花费的总时间,包括分块检索和回答生成。 |
| 检查 LLM (Check LLM) | 验证指定 LLM 的时间。 |
| 创建检索器 (Create retriever) | 创建分块检索器的时间。 |
| 绑定嵌入 (Bind embedding) | 初始化嵌入模型实例的时间。 |
| 绑定 LLM (Bind LLM) | 初始化 LLM 实例的时间。 |
| 微调问题 (Tune question) | 利用多轮对话上下文优化用户查询的时间。 |
| 绑定重排器 (Bind reranker) | 为分块检索初始化重排器模型实例的时间。 |
| 生成关键词 (Generate keywords) | 从用户查询中提取关键词的时间。 |
| 检索 (Retrieval) | 检索分块的时间。 |
| 生成回答 (Generate answer) | 生成回答的时间。 |