开始 AI 聊天 (Start AI Chat)
使用已配置的聊天助手启动 AI 辅助对话。
RAGFlow 中的聊天基于特定数据集 (Dataset) 或多个数据集。创建数据集、完成文件解析 (Parse) 并运行检索测试后,您就可以开始 AI 对话了。
开始 AI 聊天
您可以通过创建助手来启动 AI 对话。
-
点击页面中上部的**聊天 (Chat)选项卡 > 创建助手,以显示您下一次对话的聊天配置 (Chat Configuration)**对话框。
RAGFlow 让您可以灵活地为每次对话选择不同的聊天模型,同时允许您在**系统模型设置 (System Model Settings)**中设置默认模型。
-
更新助手特定设置:
- 助手名称 (Assistant name):您的聊天助手的名称。每个助手对应一个对话,该对话具有数据集、提示词、混合检索 (Hybrid Search) 配置和大语言模型 (Large Language Model, LLM) 设置的独特组合。
- 空回复 (Empty response):
- 如果您希望将 RAGFlow 的回答局限在您的地方性数据集中,请在此处留下回复。这样,当它未能检索到答案时,将统一回复您在此处设置的内容。
- 如果您希望 RAGFlow 在未能从数据集中检索到答案时进行即兴发挥,请将其留空,这可能会导致幻觉 (hallucinations)。
- 显示引用 (Show quote):这是 RAGFlow 的一项关键功能,默认启用。RAGFlow 并不像黑盒子那样工作,而是清晰地显示其回答所依据的信息来源。
- 选择相应的数据集。您可以选择一个或多个数据集,但请确保它们使用相同的嵌入模型 (Embedding Model),否则会发生错误。
-
更新提示词特定设置:
- 在**系统提示词 (System)**中,您填写 LLM 的提示词,初次使用时也可以保持默认提示词不变。
- 相似度阈值 (Similarity threshold) 设置每个文本块 (Chunk) 的相似度“门槛”。默认值为 0.2。低于此相似度得分的文本块将被过滤掉,不参与最终的回复生成。
- 向量相似度权重 (Vector similarity weight) 默认设置为 0.3。RAGFlow 使用混合评分系统来评估不同文本块的相关性。此值设置了混合评分中分配给向量相似度部分的权重。
- 如果**重排模型 (Rerank model)**留空,则混合评分系统会使用关键词相似度和向量相似度,而分配给关键词相似度部分的默认权重为 1-0.3=0.7。
- 如果选择了重排模型 (Rerank model),则混合评分系统会使用关键词相似度和重排器 (Reranker) 得分,而分配给重排器得分的默认权重为 1-0.7=0.3。
- 前 N 个 (Top N) 决定了喂给 LLM 的最大分块数量。换言之,即使检索到更多的分块,也只有前 N 个分块会被作为输入提供。
- 多轮优化 (Multi-turn optimization) 在多轮对话中利用现有上下文增强用户查询。它默认启用。启用后,它将消耗额外的 LLM Token,并显著增加生成回答的时间。
- 使用知识图谱 (Use knowledge graph) 表示在检索时是否使用指定数据集中的知识图谱来进行多跳问答。启用后,这会涉及对实体、关系和社区报告块的迭代搜索,从而大大增加检索时间。
- 推理 (Reasoning) 表示是否通过类似 DeepSeek-R1 / OpenAI o1 的推理过程来生成答案。一旦启用,当遇到未知主题时,聊天模型在问答过程中会自动集成深度研究 (Deep Research)。这涉及聊天模型动态搜索外部知识,并通过推理生成最终答案。
- 重排模型 (Rerank model) 设置要使用的重排器模型。默认留空。
- 如果重排模型留空,则混合评分系统会使用关键词相似度和向量相似度,而分配给向量相似度部分的默认权重为 1-0.7=0.3。
- 如果选择了重排模型,则混合评分系统会使用关键词相似度和重排器得分,而分配给重排器得分的默认权重为 1-0.7=0.3。
- 跨语言搜索 (Cross-language search):可选
从下拉菜单中选择一个或多个目标语言。系统默认的聊天模型会将您的查询翻译成所选的目标语言。这种翻译确保了跨语言的准确语义匹配,使您能够检索到相关的结果,而不受语言差异的限制。- 选择目标语言时,请确保这些语言存在于数据集中,以保证有效的检索。
- 如果未选择任何目标语言,系统将仅以您查询的语言进行搜索,这可能会漏掉其他语言的相关信息。
- 变量 (Variable) 是指在系统提示词中使用的变量(键)。
{knowledge}是保留变量。点击**添加 (Add)**可以为系统提示词添加更多变量。
-
更新模型特定设置:
- 在**模型 (Model)中:您选择聊天模型。虽然您已在系统模型设置 (System Model Settings)**中选择了默认聊天模型,但 RAGFlow 允许您为该对话选择替代的聊天模型。
- 创造力 (Creativity):这是温度 (Temperature)、核采样 (Top P)、存在惩罚 (Presence penalty) 和频率惩罚 (Frequency penalty) 设置的快捷方式,指示模型的自由度。从发散 (Improvise)、精准 (Precise) 到平衡 (Balance),每个预设配置都对应着温度、核采样、存在惩罚和频率惩罚的独特组合。
此参数有三个选项:- 发散 (Improvise):产生更具创造性的回答。
- 精准 (Precise):(默认)产生更保守的回答。
- 平衡 (Balance):介于发散和精准之间的折中方案。
- 温度 (Temperature):模型输出的随机程度。默认为 0.1。
- 较低的值会导致更具确定性和可预测性的输出。
- 较高的值会导致更具创造性和多样性的输出。
- 温度为零将导致针对相同提示词产生完全相同的输出。
- 核采样 (Top P):核采样。
- 通过设置阈值 P 并将采样限制在累积概率超过 P 的 Token,从而降低生成重复或不自然文本的可能性。
- 默认为 0.3。
- 存在惩罚 (Presence penalty):鼓励模型在回答中包含更多样化的 Token。
- 较高的存在惩罚值会使模型更有可能生成尚未包含在已生成文本中的 Token。
- 默认为 0.4。
- 频率惩罚 (Frequency penalty):防止模型在生成的文本中过于频繁地重复相同的词或短语。
- 较高的频率惩罚值会使模型在使用重复的 Token 时更加保守。
- 默认为 0.7。
-
现在,开始您的对话体验:

提示
-
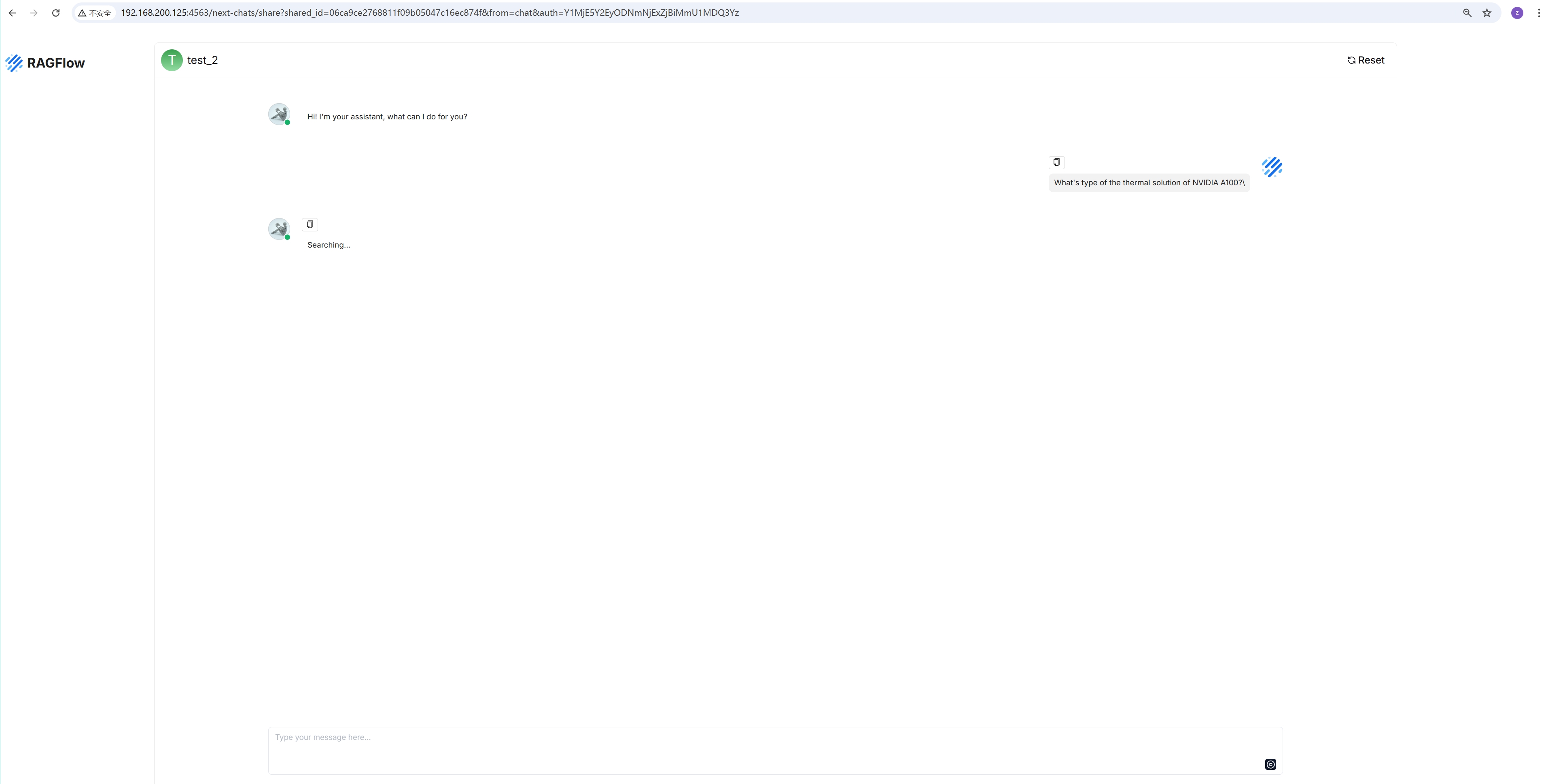
点击回答上方的灯泡图标以查看展开的系统提示词:
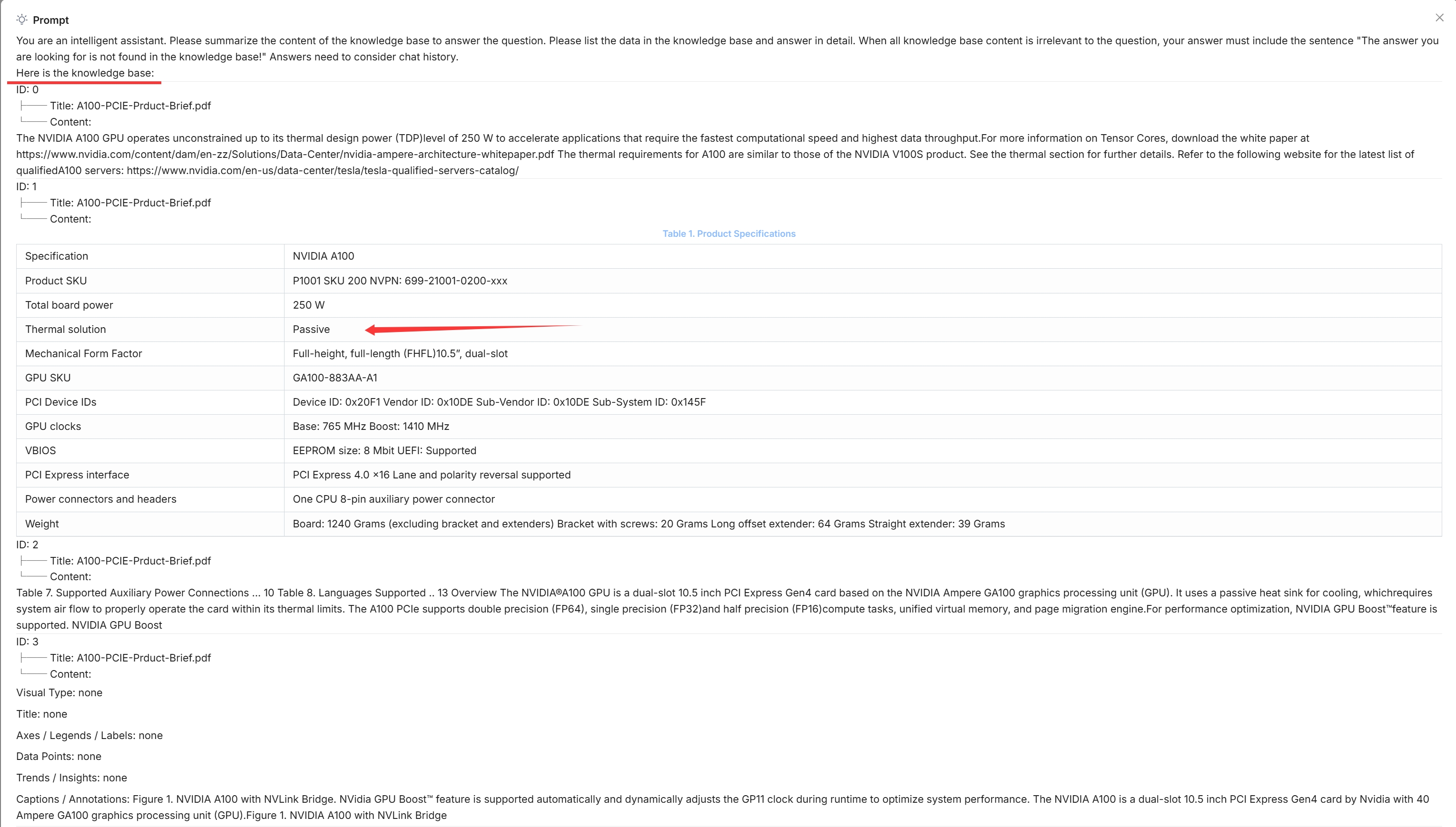
该灯泡图标仅对当前对话可用。
-
向下滚动展开的提示词可以查看每个任务所消耗的时间:

更新现有聊天助手的设置

将聊天能力集成到您的应用程序或网页中
RAGFlow 提供了 HTTP 和 Python API,方便您将 RAGFlow 的能力集成到您的应用程序中。阅读以下文档获取更多信息:
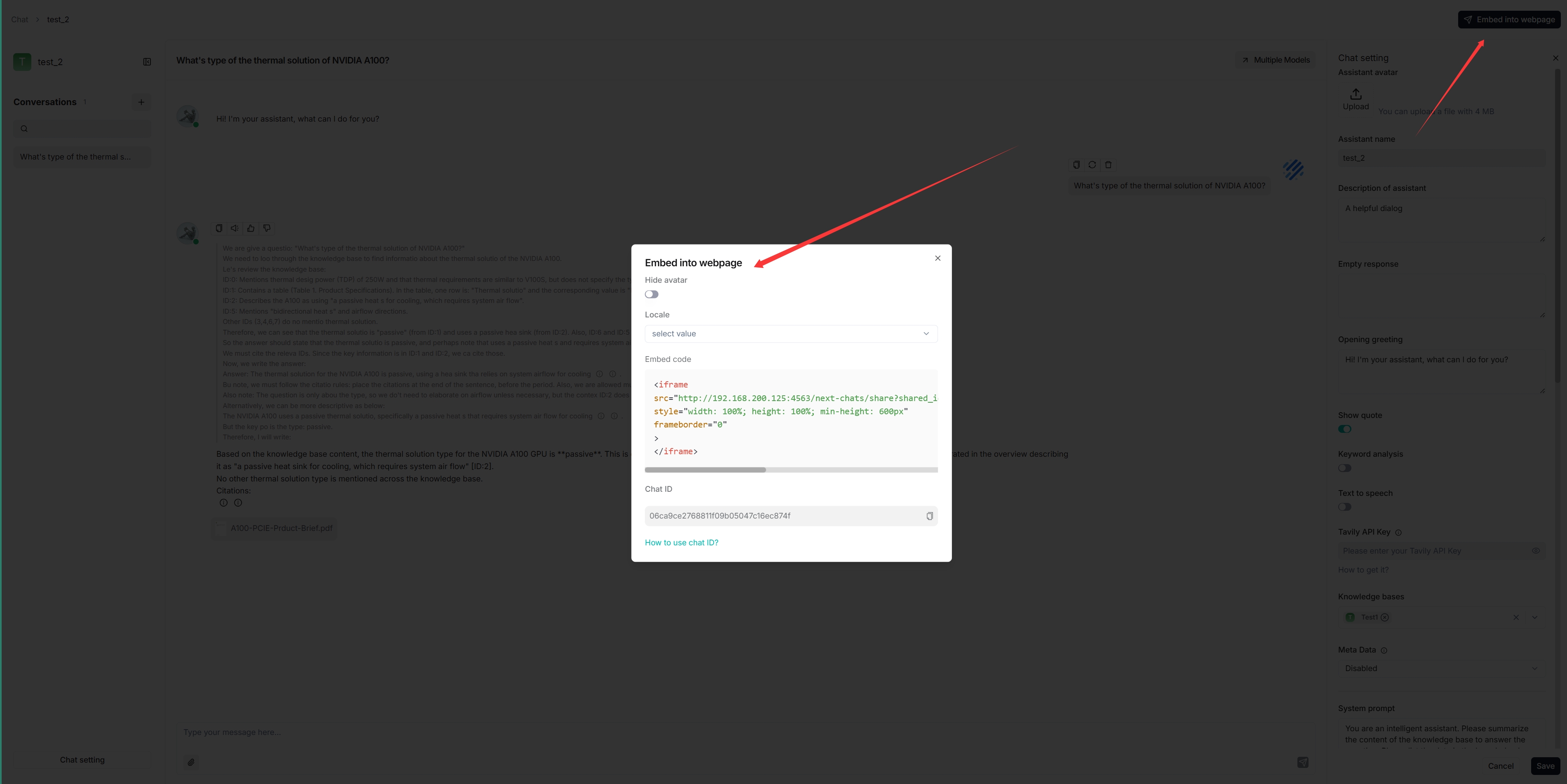
您可以使用 iframe 将创建的聊天助手嵌入到第三方网页中:
-
在继续之前,您必须获取 API 密钥 (API Key);否则,将显示错误消息。
-
将鼠标悬停在目标聊天助手上 > 编辑,以显示 iframe 窗口:
-
复制 iframe 并将其嵌入到您的网页中。