运行检索测试 (Run retrieval test)
对你的数据集进行检索测试,以检查是否能够检索到所需的文本块 (Chunk)。
文件上传并解析完成后,建议你在配置聊天助手之前先运行检索测试。运行检索测试绝不是一个不必要或多余的步骤!就像调校精密仪器一样,RAGFlow 需要仔细调优才能提供最佳的问答性能。你的数据集设置、聊天助手配置以及指定的大模型和小模型都会显著影响最终结果。运行检索测试可以验证是否能找回所需的文本块,从而让你快速发现可以改进的地方或定位需要解决的任何问题。例如,在调试问答系统时,如果你知道能够检索到正确的文本块,你就可以把精力集中在其他方面。例如,在 Issue #5627 中,最终发现问题是由 LLM 的局限性引起的。
在检索测试中,通过你指定的分块方法创建的文本块将使用混合检索 (Hybrid Search) 进行召回。这种检索根据你的设置,将加权的关键字相似度与加权的向量余弦相似度或加权的重排得分相结合:
- 如果未选择重排模型 (Rerank Model),加权的关键字相似度将与加权的向量余弦相似度相结合。
- 如果选择了重排模型,加权的关键字相似度将与加权的向量重排得分相结合。
相比之下,通过 构建知识图谱 创建的文本块将仅使用向量余弦相似度进行检索。
前提条件 (Prerequisites)
- 在运行检索测试之前,确保文件已上传并成功解析。
- 在启用 使用知识图谱 (Use knowledge graph) 之前,必须成功构建知识图谱 (Knowledge Graph)。
参数配置 (Configurations)
相似度阈值 (Similarity threshold)
这设置了检索文本块的门槛:相似度低于该阈值的块将被过滤掉。默认情况下,阈值设置为 0.2。这意味着只有混合相似度得分达到 20 或更高的块才会被检索出来。
向量相似度权重 (Vector similarity weight)
这设置了向量相似度在综合相似度得分中的权重,无论是与向量余弦相似度配合使用还是与重排得分配合使用。默认情况下设置为 0.3,使另一个组件的权重为 0.7 (1 - 0.3)。
重排模型 (Rerank model)
- 如果留空,RAGFlow 将使用加权关键字相似度和加权向量余弦相似度的组合。
- 如果选择了重排模型,加权关键字相似度将与加权向量重排得分相结合。
使用重排模型 (Rerank Model) 会显著增加接收响应的时间。
使用知识图谱 (Use knowledge graph)
在知识图谱 (Knowledge Graph) 中,实体描述、关系描述或社区报告都作为独立的块存在。此开关表示是否将这些块添加到检索中。
该开关默认禁用。启用后,RAGFlow 在检索测试期间将执行以下操作:
- 使用 LLM 从你的查询中提取实体和实体类型。
- 使用提取的实体类型,根据它们的 PageRank 值从图谱中检索前 N 个实体。
- 使用提取的查询实体的向量嵌入,在图谱中查找相似实体及其 N 步(N-hop)关系。
- 使用查询的向量嵌入从图谱中检索相似的关系。
- 将每个检索到的实体和关系的 PageRank 值与其与查询的相似度得分相乘,对它们进行排序,并返回前 n 个作为最终检索结果。
- 检索包含最终检索中最多实体的社区报告。
检索到的实体描述、关系描述和排名前 1 的社区报告将被发送到大语言模型 (LLM) 用于内容生成。
在检索测试中使用知识图谱会显著增加接收响应的时间。
跨语言检索 (Cross-language search)
要执行 跨语言检索,请从下拉菜单中选择一个或多个目标语言。然后,系统的默认聊天模型会将你在测试文本框中输入的查询翻译为选定的目标语言。这种翻译确保了跨语言的准确语义匹配,从而允许你检索到相关的结果,而不受语言差异的影响。
- 在选择目标语言时,请确保这些语言在数据集 (Dataset) 中存在,以保证检索的有效性。
- 如果没有选择目标语言,系统将仅在你查询的语言中进行检索,这可能会导致遗漏其他语言中的相关信息。
测试文本 (Test text)
此字段是你输入测试查询的地方。
操作步骤 (Procedure)
-
导航到你数据集的 检索测试 (Retrieval testing) 页面,在 测试文本 (Test text) 中输入你的查询,然后点击 测试 (Testing) 运行测试。
-
如果结果不理想,调整参数配置部分中列出的选项,并重新运行测试。
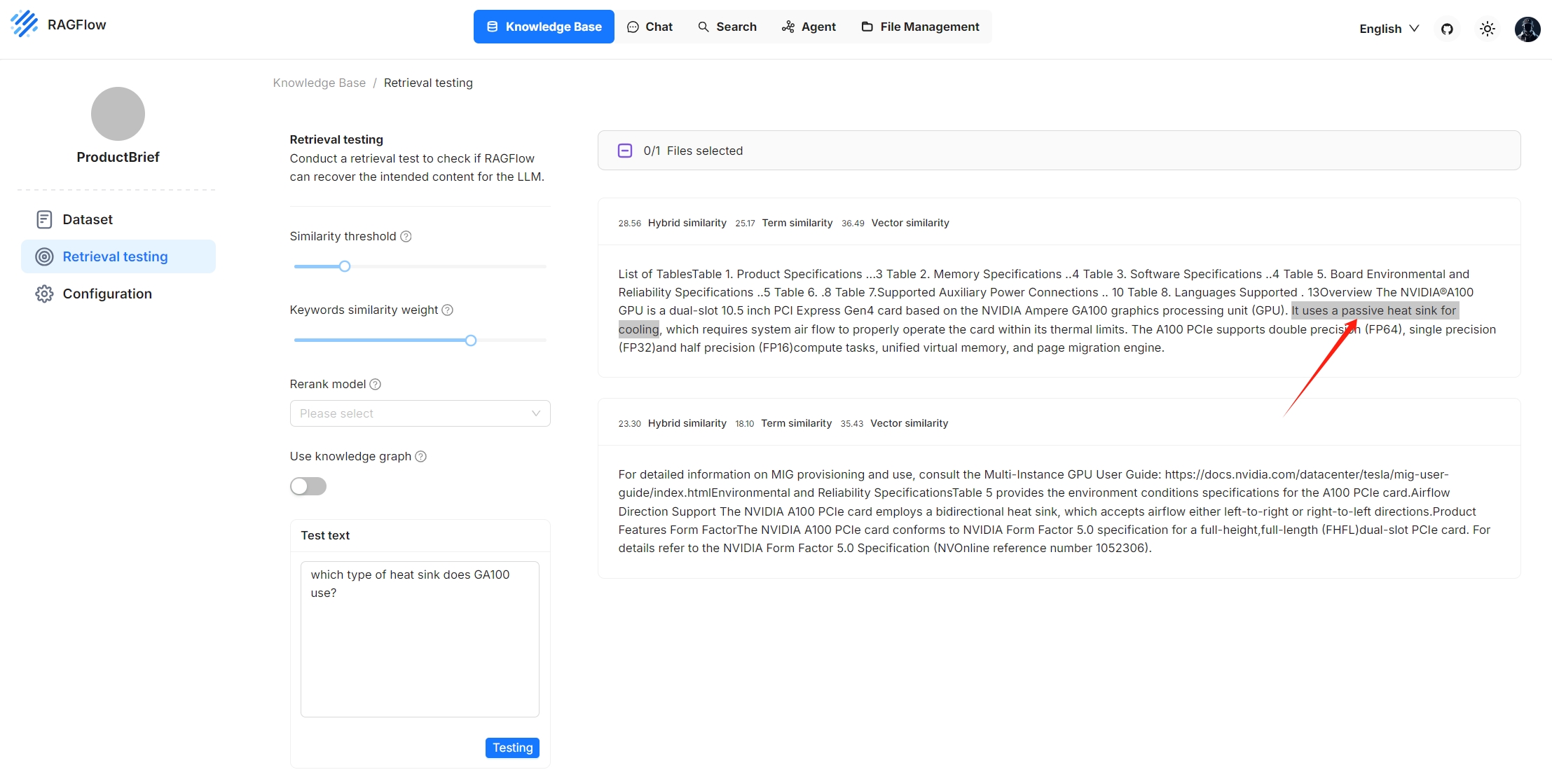
以下是未使用知识图谱进行的检索测试的截图。它展示了结合加权关键字相似度和加权向量余弦相似度的混合检索。总混合相似度得分为 28.56,计算方式为:25.17(词项相似度得分)x 0.7 + 36.49(向量相似度得分)x 0.3:
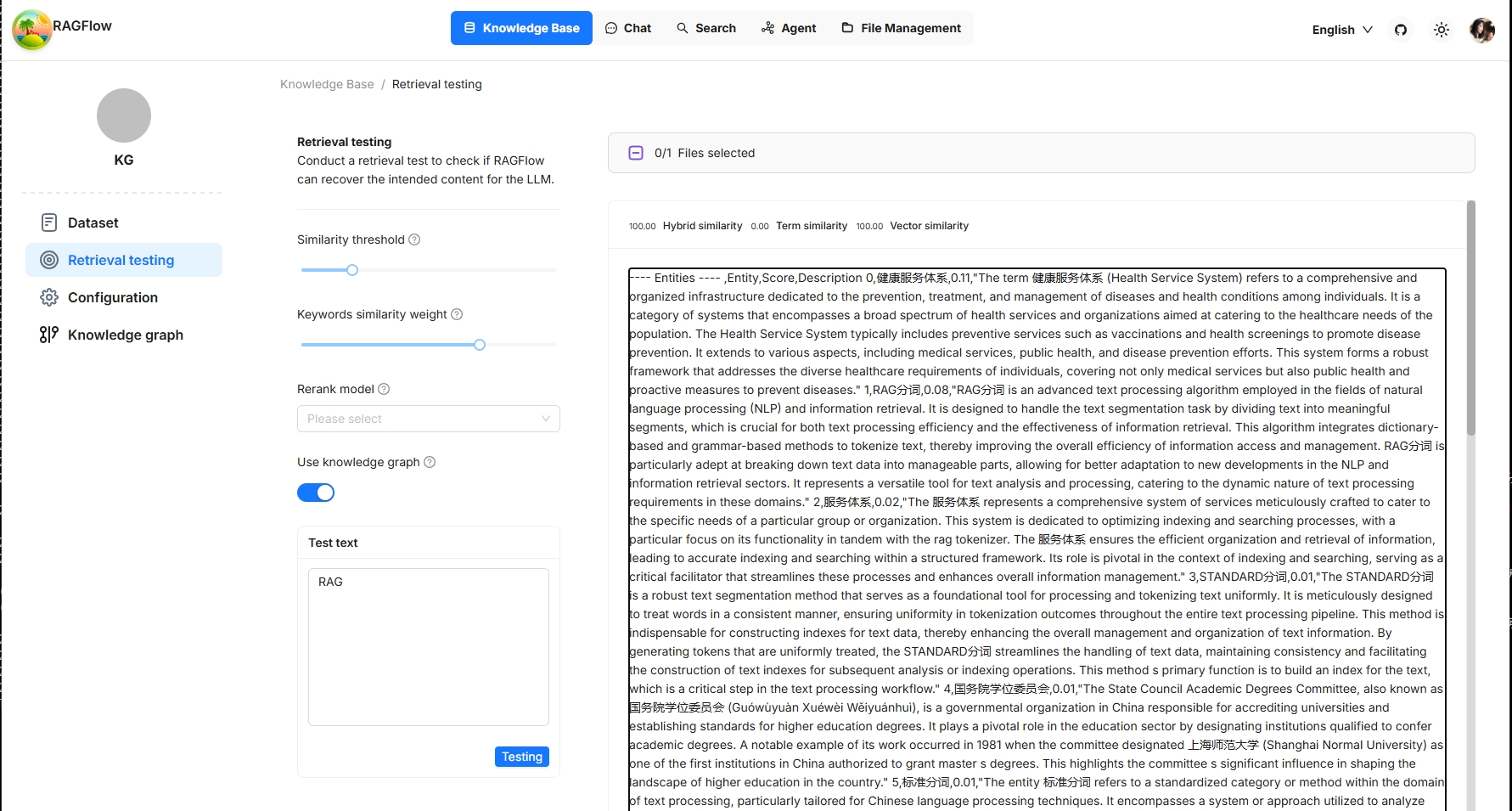
以下是使用知识图谱进行的检索测试的截图。它显示了对于由知识图谱生成的块,仅使用向量余弦相似度:
如果你调整了默认设置(如关键字相似度权重或相似度阈值)以达到最佳效果,请注意这些更改不会自动保存。你必须将它们手动应用到聊天助手设置或 检索 (Retrieval) 智能体组件设置中。
常见问题 (Frequently asked questions)
启用“使用知识图谱”开关时会使用大语言模型 (LLM) 吗?
是的,大语言模型 (LLM) 将参与分析你的查询并从知识图谱中提取相关的实体和关系。这也解释了为什么会消耗额外的 Token 和时间。