配置数据集 (Configure dataset)
RAGFlow 的大多数聊天助手和智能体 (Agent) 都是基于数据集的。RAGFlow 的每个数据集都是一个知识源,它将从你本地机器上传的文件以及在 RAGFlow 文件系统中生成的文件引用*解析 (Parse)*为真正的“知识”,供未来的 AI 聊天使用。本指南将演示数据集功能的一些基本用法,涵盖以下主题:
- 创建数据集 (Create a dataset)
- 配置数据集 (Configure a dataset)
- 搜索数据集 (Search for a dataset)
- 删除数据集 (Delete a dataset)
创建数据集 (Create dataset)
通过多个数据集,你可以构建更灵活、多样化的问答系统。创建你的第一个数据集:
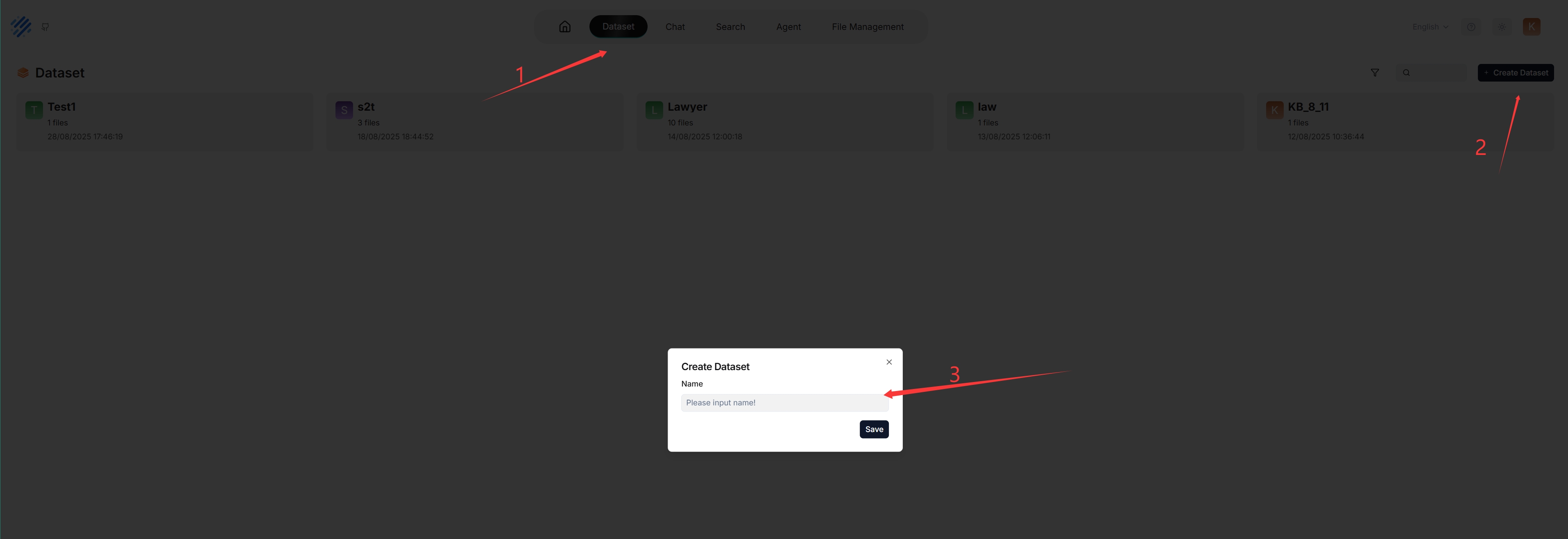
每次创建数据集时,都会在 root/.knowledgebase 目录下生成一个同名文件夹。
配置数据集 (Configure dataset)
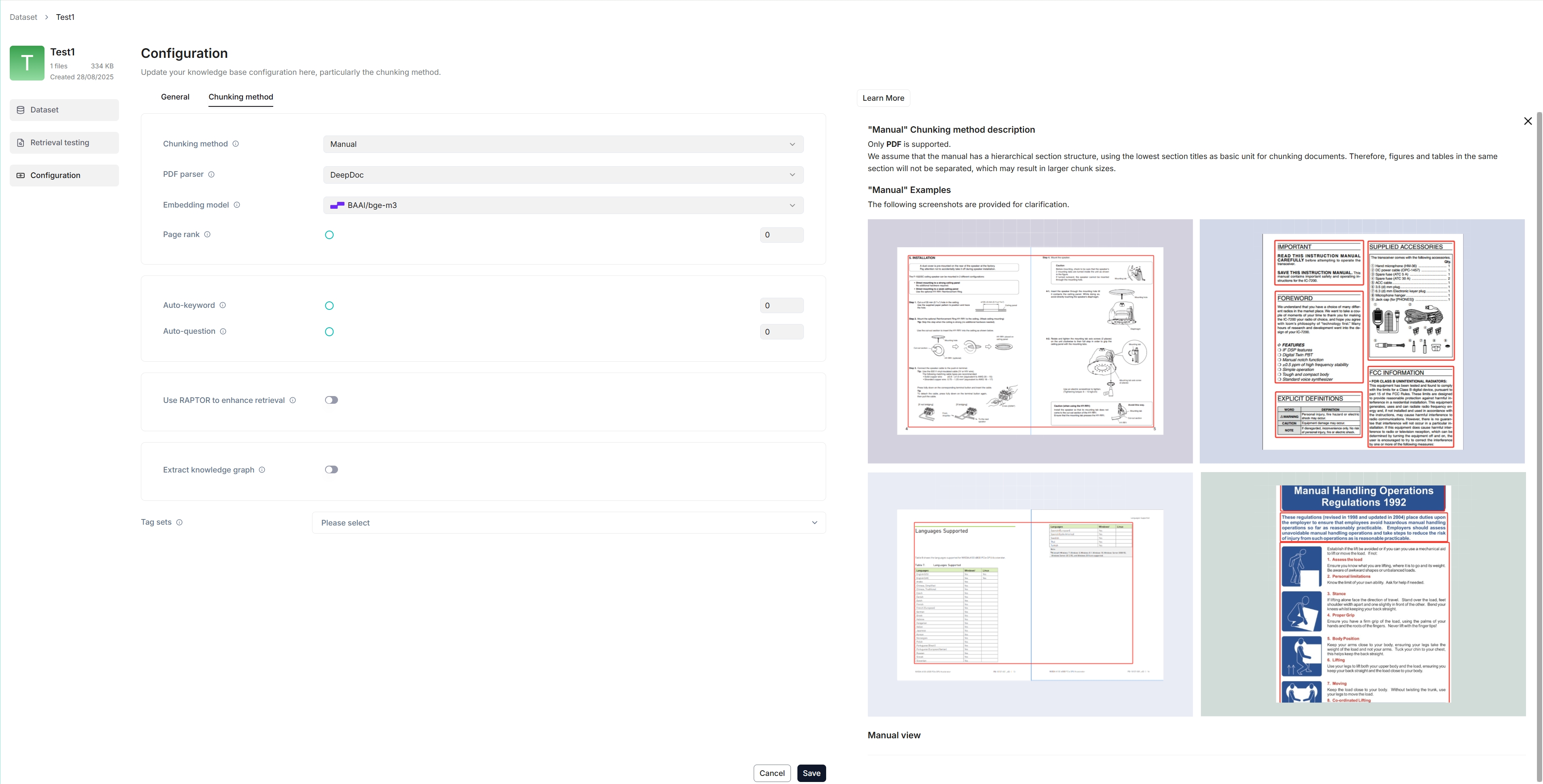
以下截图显示了数据集的配置页面。正确配置数据集对于未来的 AI 聊天至关重要。例如,选择错误的嵌入模型 (Embedding Model) 或分块 (Chunking) 方法会导致意外的语义丢失或聊天中答案不匹配。
本节涵盖以下主题:
- 选择分块方法
- 选择嵌入模型
- 上传文件
- 解析文件
- 干预文件解析结果
- 运行检索测试
选择分块方法 (Select chunking method)
RAGFlow 提供了多种内置的分块模板,以方便对不同布局的文件进行分块并确保语义完整性。从 解析类型 (Parse type) 下的 内置 (Built-in) 分块方法下拉菜单中,你可以选择适合你文件布局和格式的默认模板。下表显示了每个支持的分块模板的说明和兼容的文件格式:
| 模板 (Template) | 描述 (Description) | 文件格式 (File format) |
|---|---|---|
| 通用 (General) | 文件根据预设的块 Token 数量进行连续分块。 | MD, MDX, DOCX, XLSX, XLS (Excel 97-2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
| 问答 (Q&A) | 检索相关信息并生成问答对以响应问题。 | XLSX, XLS (Excel 97-2003), CSV/TXT |
| 简历 (Resume) | 仅限企业版。你也可以在 cloud.ragflow.io 上试用。 | DOCX, PDF, TXT |
| 手动 (Manual) | ||
| 表格 (Table) | 表格模式使用 TSI 技术进行高效的数据解析。 | XLSX, XLS (Excel 97-2003), CSV/TXT |
| 论文 (Paper) | ||
| 图书 (Book) | DOCX, PDF, TXT | |
| 法律 (Laws) | DOCX, PDF, TXT | |
| 演示文稿 (Presentation) | PDF, PPTX | |
| 图片 (Picture) | JPEG, JPG, PNG, TIF, GIF | |
| 单文档 (One) | 每个文档整体作为一个块进行分块。 | DOCX, XLSX, XLS (Excel 97-2003), PDF, TXT |
| 标签 (Tag) | 该数据集用作其他数据集的标签集。 | XLSX, CSV/TXT |
你还可以文件页面上更改文件的分块方法。
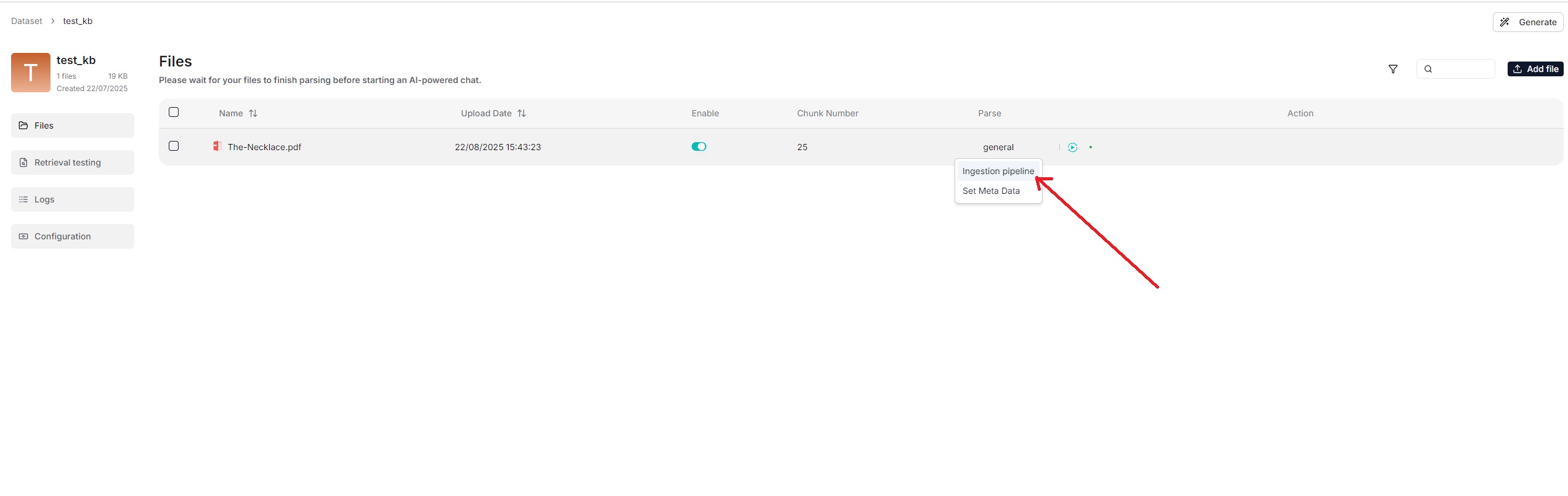
从 v0.21.0 版本开始,RAGFlow 支持导入流水线 (Ingestion Pipeline),以实现自定义数据导入和清洗工作流。
使用自定义数据流水线:
-
在 智能体 (Agent) 页面上,点击 + 创建智能体 (Create agent) > 空白创建 (Create from blank)。
-
选择 导入流水线 (Ingestion pipeline) 并在大弹窗中命名你的数据流水线,然后点击 保存 (Save) 显示数据流水线画布。
-
更新你的数据流水线后,点击画布右上角的 保存 (Save)。
-
导航到你数据集的 配置 (Configuration) 页面,在 导入流水线 (Ingestion pipeline) 中选择 选择流水线 (Choose pipeline)。
你保存的数据流水线将显示在下方的下拉菜单中。
选择嵌入模型 (Select embedding model)
嵌入模型 (Embedding Model) 将分块转换为向量嵌入。一旦数据集中生成了块,就无法再更改嵌入模型。要切换到不同的嵌入模型,你必须删除该数据集中所有现有的块。显而易见的原因是,我们必须确保特定数据集中的文件使用相同的嵌入模型转换为向量嵌入(确保它们在相同的嵌入空间中进行比较)。
某些嵌入模型针对特定语言进行了优化,因此如果你使用它们来嵌入其他语言的文档,性能可能会受到影响。
上传文件 (Upload file)
- RAGFlow 的文件系统允许你将一个文件链接到多个数据集,在这种情况下,每个目标数据集都持有该文件的引用。
- 在 知识库 (Knowledge Base) 中,你还可以选择从本地机器向数据集上传单个文件或文件夹(批量上传),在这种情况下,数据集将持有文件副本。
虽然直接将文件上传到数据集似乎更方便,但我们强烈建议先将文件上传到 RAGFlow 的文件系统,然后将其链接到目标数据集。这样,你可以避免永久删除已上传到数据集的文件。
解析文件 (Parse file)
文件解析 (Parse) 是数据集配置中的一个关键主题。RAGFlow 中的文件解析有双重含义:根据文件布局对文件进行分块,并对这些分块构建嵌入索引和全文(关键字)索引。选择分块方法和嵌入模型后,你可以开始解析文件:
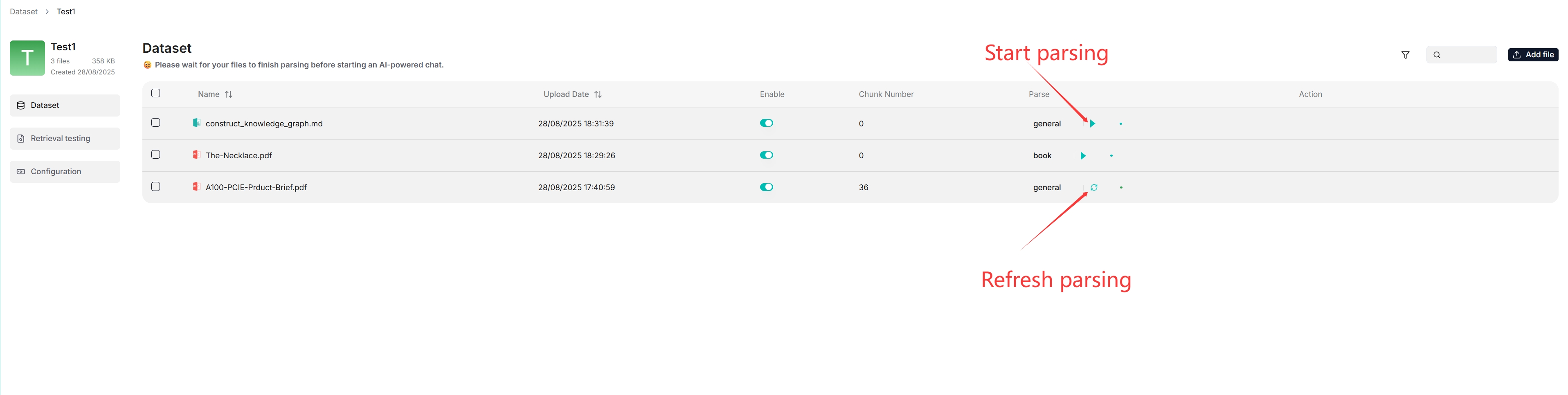
- 如上所示,RAGFlow 允许你对特定文件使用不同的分块方法,提供了超出默认方法的灵活性。
- 如上所示,RAGFlow 允许你启用或禁用单个文件,从而对基于数据集的 AI 聊天提供更精细的控制。
干预文件解析结果 (Intervene with file parsing results)
RAGFlow 具有可视化和可解释性的特点,允许你查看分块结果并在必要时进行干预。步骤如下:
-
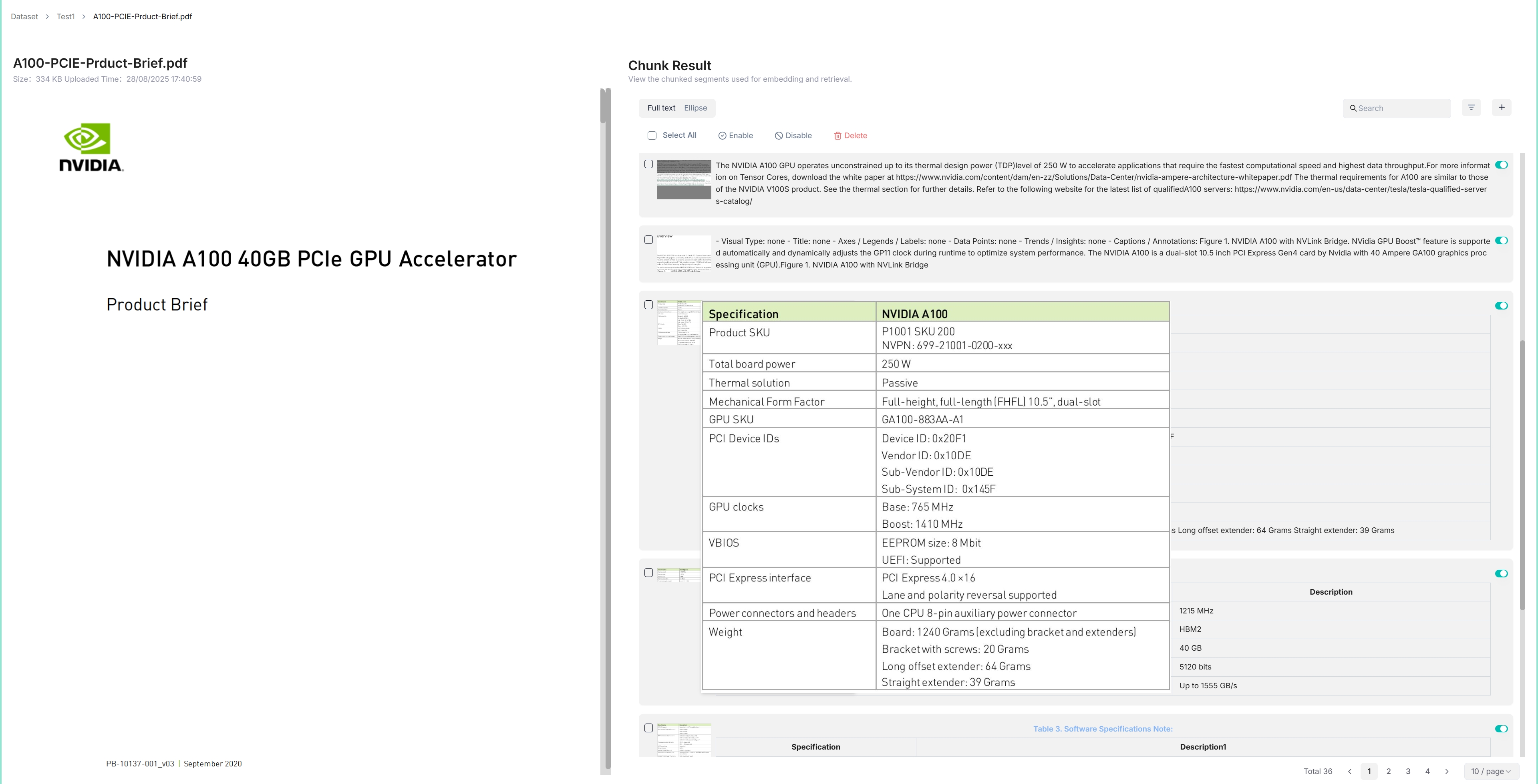
点击已完成文件解析的文件以查看分块结果:
系统将带你进入 块 (Chunk) 页面:
-
将鼠标悬停在每个快照上以快速查看每个块。
-
双击分块的文本以添加关键字、问题、标签,或在必要时进行手动修改:
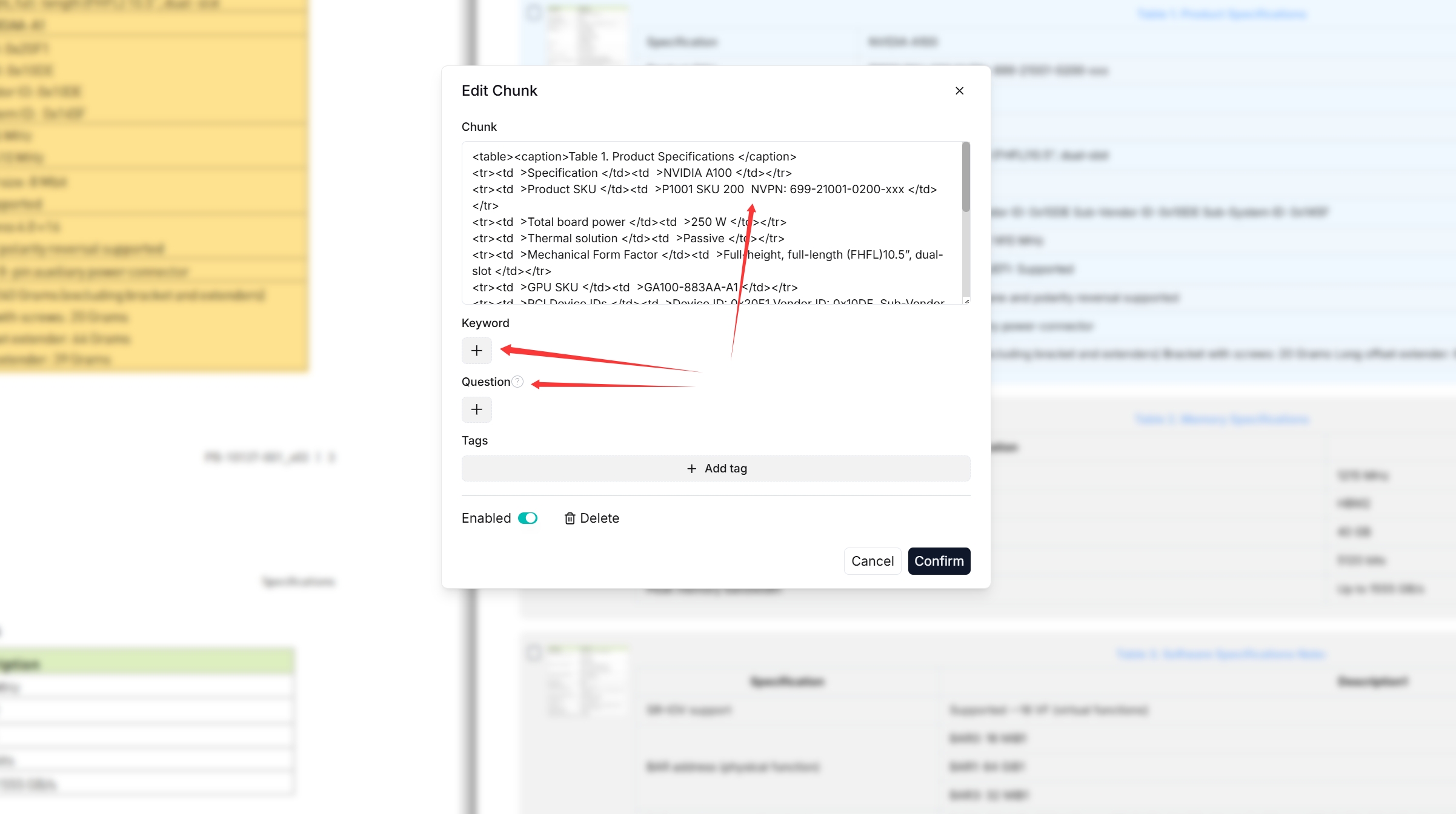
你可以向文件块中添加关键字,以提高其在包含这些关键字的查询中的排名。此操作会增加其关键字权重,并可以改善其在搜索列表中的位置。
-
在检索测试中,在 测试文本 (Test text) 中输入一个简短的问题,以仔细检查你的配置是否生效:
如下所示,RAGFlow 会返回真实的引用。
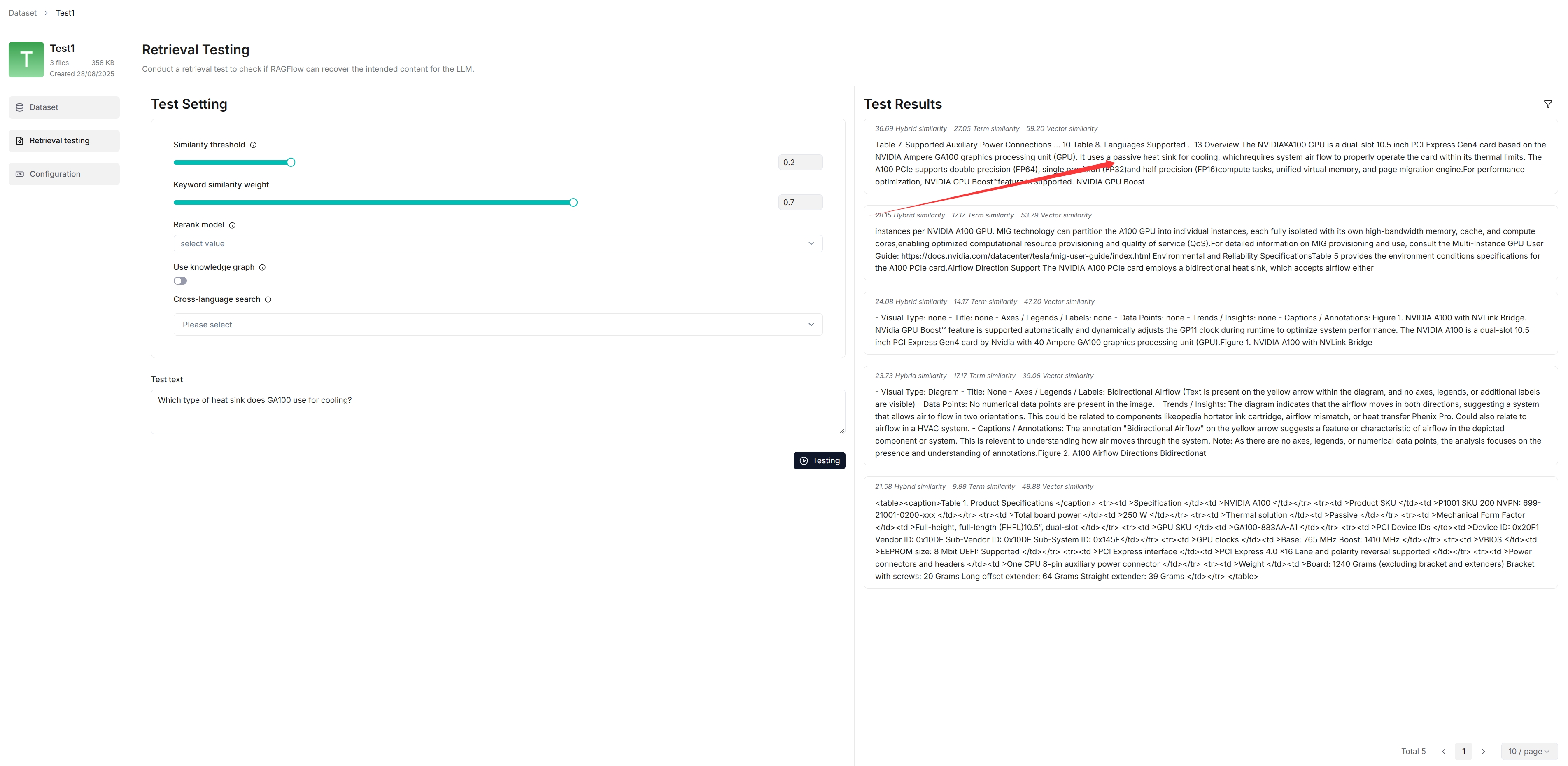
运行检索测试 (Run retrieval testing)
RAGFlow 在其聊天中使用了全文检索和向量检索的混合检索 (Hybrid Search) 模式。在设置 AI 聊天之前,建议调整以下参数,以确保所需信息始终能出现在答案中:
- 相似度阈值 (Similarity threshold):相似度低于该阈值的块将被过滤。默认设置为 0.2。
- 向量相似度权重 (Vector similarity weight):向量相似度对总分的贡献百分比。默认设置为 0.3。
详情请参阅 运行检索测试。
搜索数据集 (Search for dataset)
截至 RAGFlow v0.25.2,搜索功能仍处于初级阶段,仅支持按名称搜索数据集。

删除数据集 (Delete dataset)
你可以删除数据集。将鼠标悬停在目标数据集卡片的三个点上,即可显示 删除 (Delete) 选项。一旦你删除数据集,root/.knowledge 目录下的相关文件夹将被自动删除。其后果是:
- 直接上传到该数据集的文件将会丢失;
- 你从 RAGFlow 文件系统中创建的文件引用将会消失,但关联的原文件仍然存在。
