配置子分块策略 (Configure child chunking strategy)
设置父子分块 (Chunking) 策略以改善检索。
在实际的检索增强生成 (Retrieval-Augmented Generation, RAG) 应用中,一个长期存在的挑战是传统“分块-嵌入-检索”流水线中的结构性张力:单个文本块 (Chunk) 既要负责语义匹配(召回),又要负责上下文理解(利用)——这两个目标在本质上是冲突的。召回需要细粒度、精确的块,而答案生成则需要连贯、信息完整的上下文。
为了解决这种冲突,RAGFlow 此前引入了目录 (Table of Contents, TOC) 增强功能,它使用大语言模型 (Large Language Model, LLM) 来生成文档结构,并在检索时基于该目录自动补充缺失的上下文。在 0.23.0 版本中,这一功能已被系统地集成到导入流水线 (Ingestion Pipeline) 中,并引入了一种全新的父子分块机制。
在该机制下,文档首先被分割成较大的父分块,每个父分块保持相对完整的语义单元以确保逻辑和背景的完整性。然后,每个父分块可以进一步细分为多个子分块,用于精确召回。在检索过程中,系统首先基于子分块定位最相关的文本段,同时自动关联并召回其对应的父分块。这种方法既保持了高度的召回相关性,又为生成阶段提供了充足保持语义背景。
例如,在处理《合规手册》时,用户关于“违约责任”的查询可能会精确检索到一个子分块,其内容为“违约罚金为合同总价的 20%”,但在没有上下文的情况下,无法明确该条款适用于“轻微违约”还是“重大违约”。利用父子分块机制,系统会将该子分块连同包含该条款完整章节的父分块一并返回。这使得大语言模型 (LLM) 能够基于更广泛的上下文做出准确判断,避免误读。
通过这种“精确检索 + 上下文补充”的双层结构,RAGFlow 在确保检索准确性的同时,显著提升了生成答案的可靠性与完整性。
操作步骤 (Procedure)
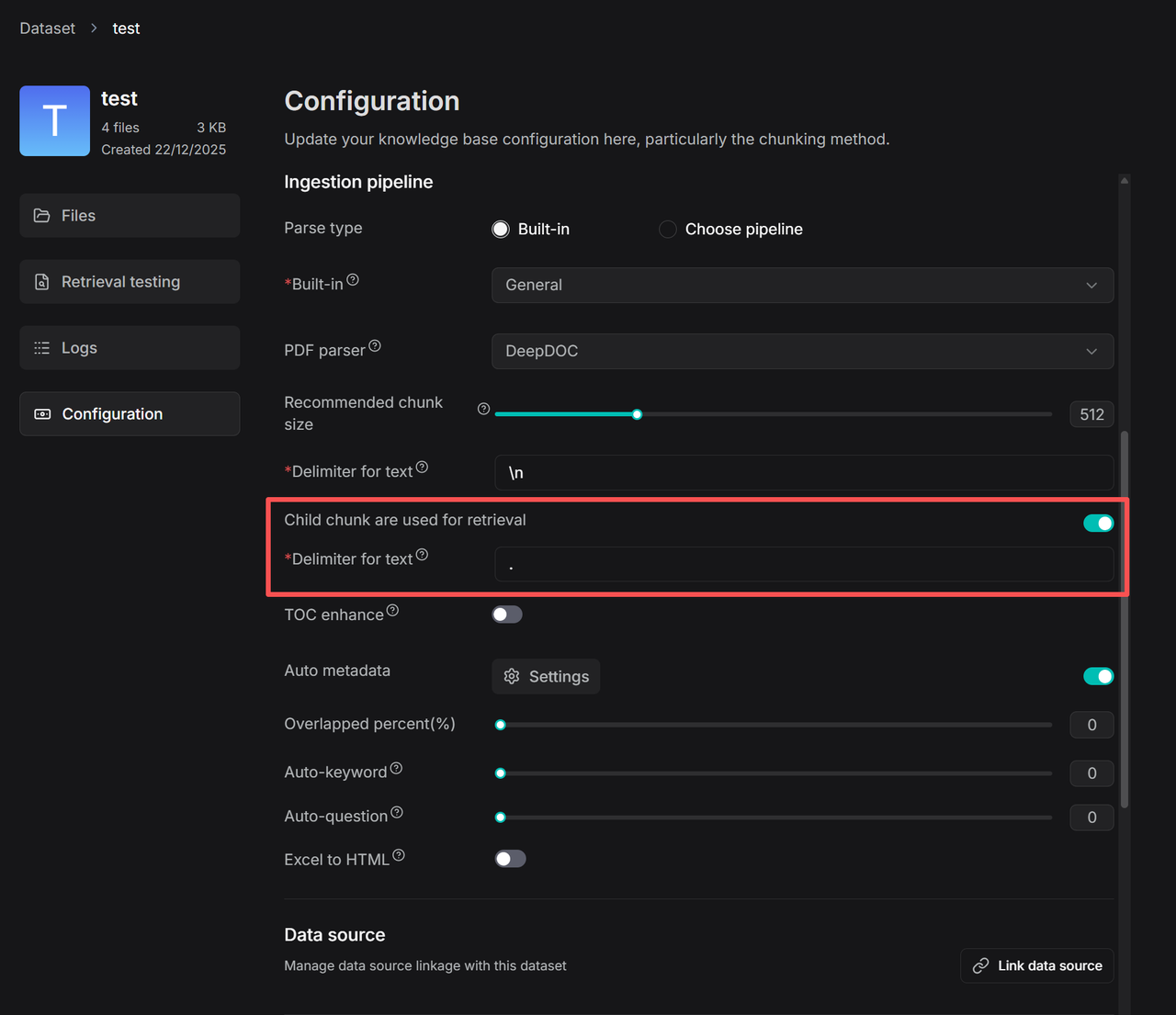
- 在数据集 (Dataset) 的 配置 页面上,找到 使用子分块进行检索 (Child chunk are used for retrieval) 开关:
-
设置子分块的分隔符。
-
此配置适用于导入流水线设置中的 分块器 (Chunker) 组件:
