自动提取元数据 (Auto-extract metadata)
从已上传的文件中自动提取元数据 (Metadata)。
RAGFlow v0.23.0 引入了自动元数据 (Auto-metadata) 功能,该功能使用大语言模型 (LLM) 自动为文件提取和生成元数据——消除了手动输入的需要。在典型的检索增强生成 (RAG) 流水线中,元数据有两个关键用途:
- 在检索阶段:过滤掉不相关的文档,缩小搜索范围以提高检索准确性。
- 在生成阶段:如果检索到某个文本块 (Chunk),其关联的元数据也会被传递给大语言模型 (LLM),从而提供关于源文档的更丰富上下文信息,以辅助答案的生成。
警告 (WARNING)
启用目录 (TOC) 提取需要大量的内存、计算资源和 Token。
操作步骤 (Procedure)
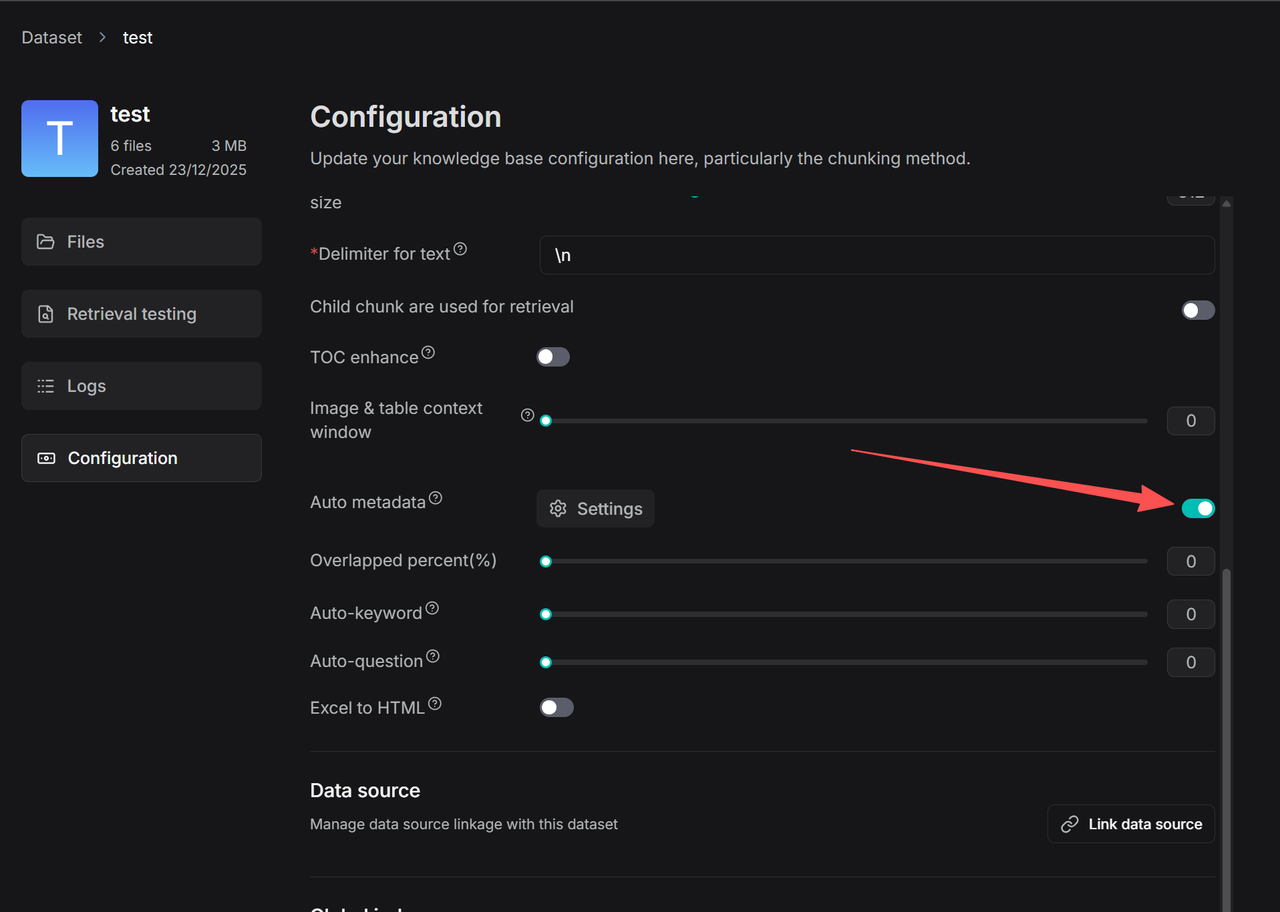
- 在数据集 (Dataset) 的 配置 (Configuration) 页面上,选择一个 索引模型 (Indexing Model),该模型将用于为该数据集生成知识图谱 (Knowledge Graph)、RAPTOR、自动元数据、自动关键字和自动问题功能。
-
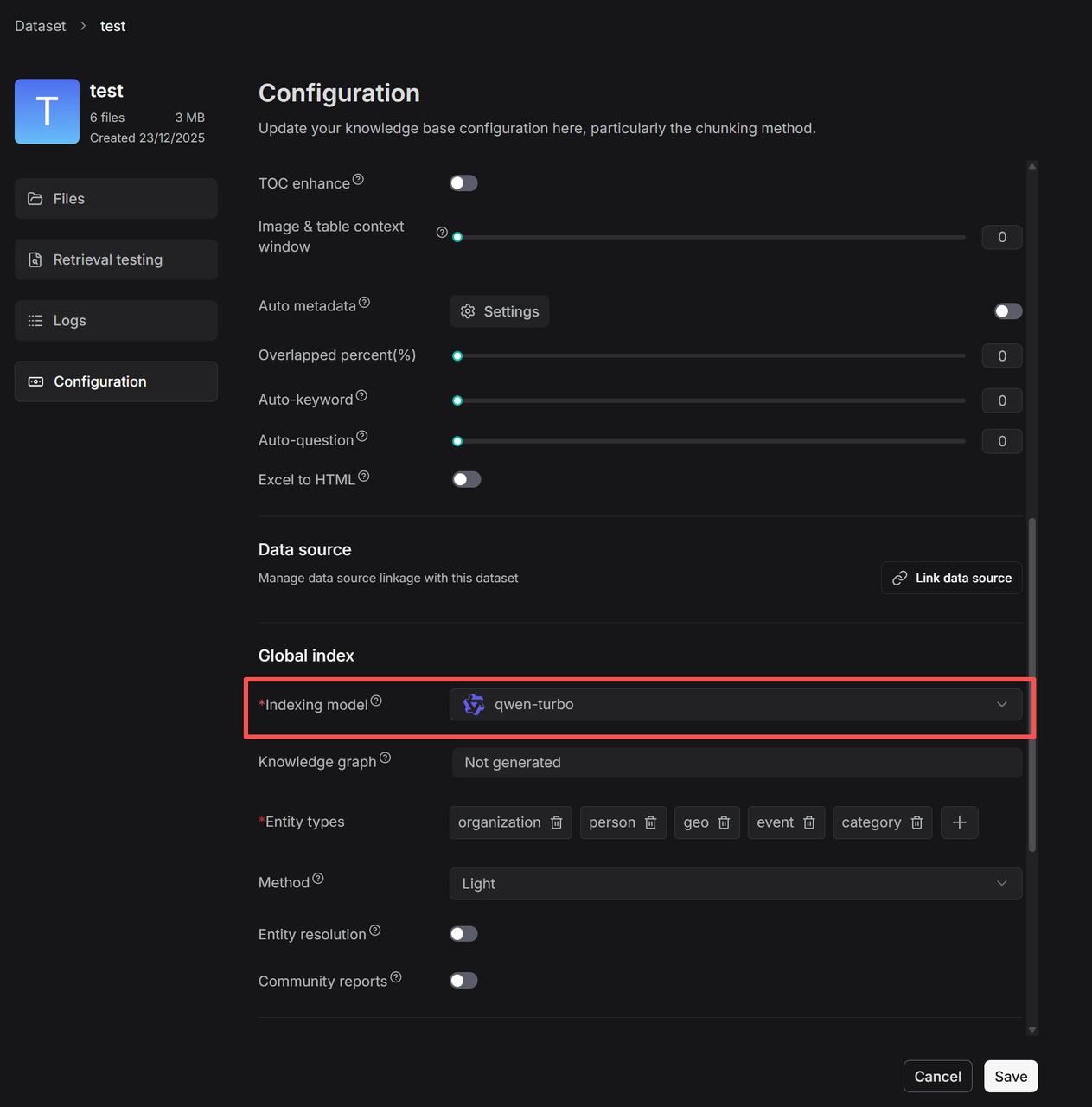
点击 自动元数据 (Auto metadata) > 设置 (Settings),进入自动生成元数据规则的配置页面。
配置自动生成元数据规则的页面将会出现。
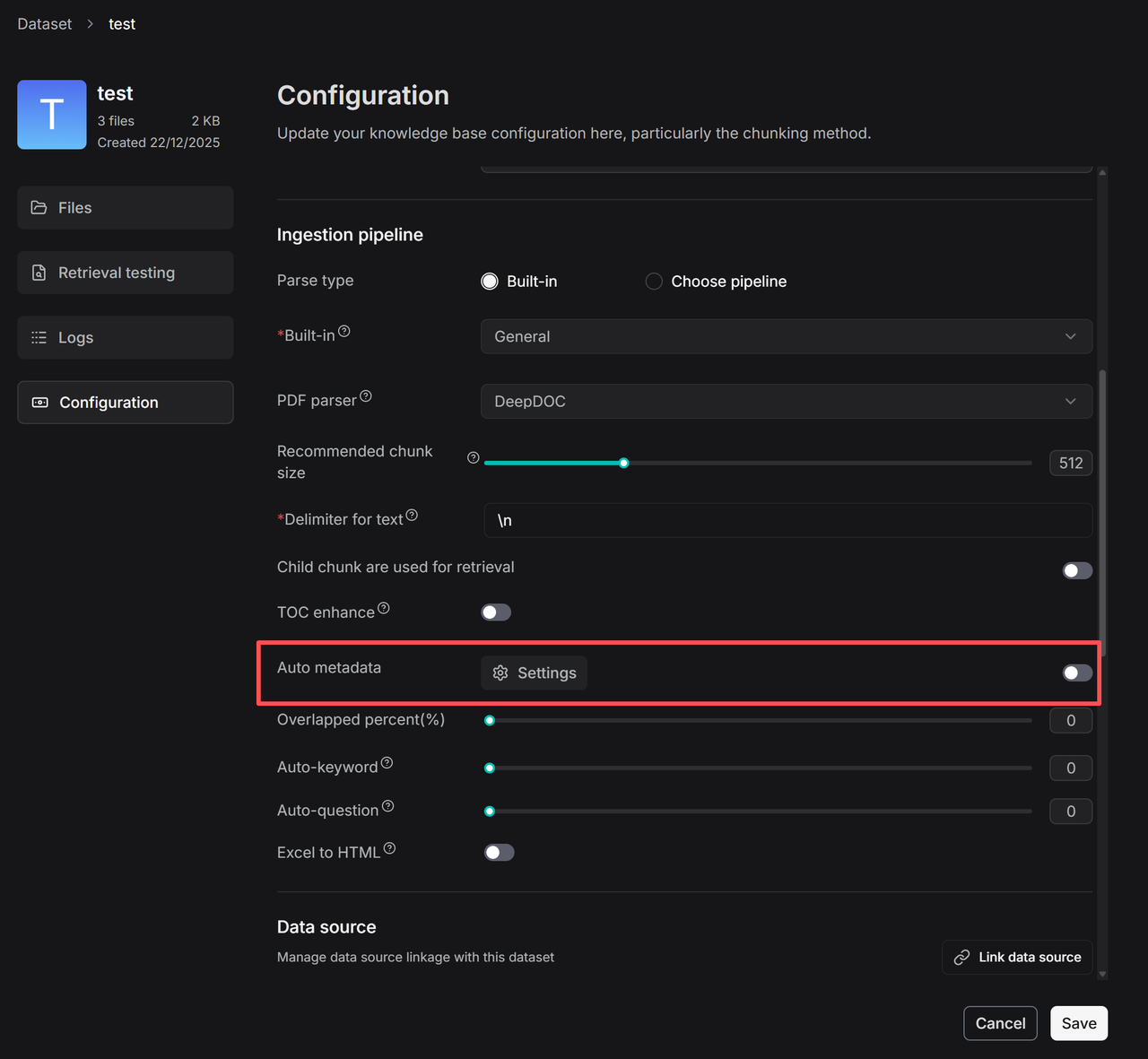
- 点击 + 添加新字段并进入配置页面。
-
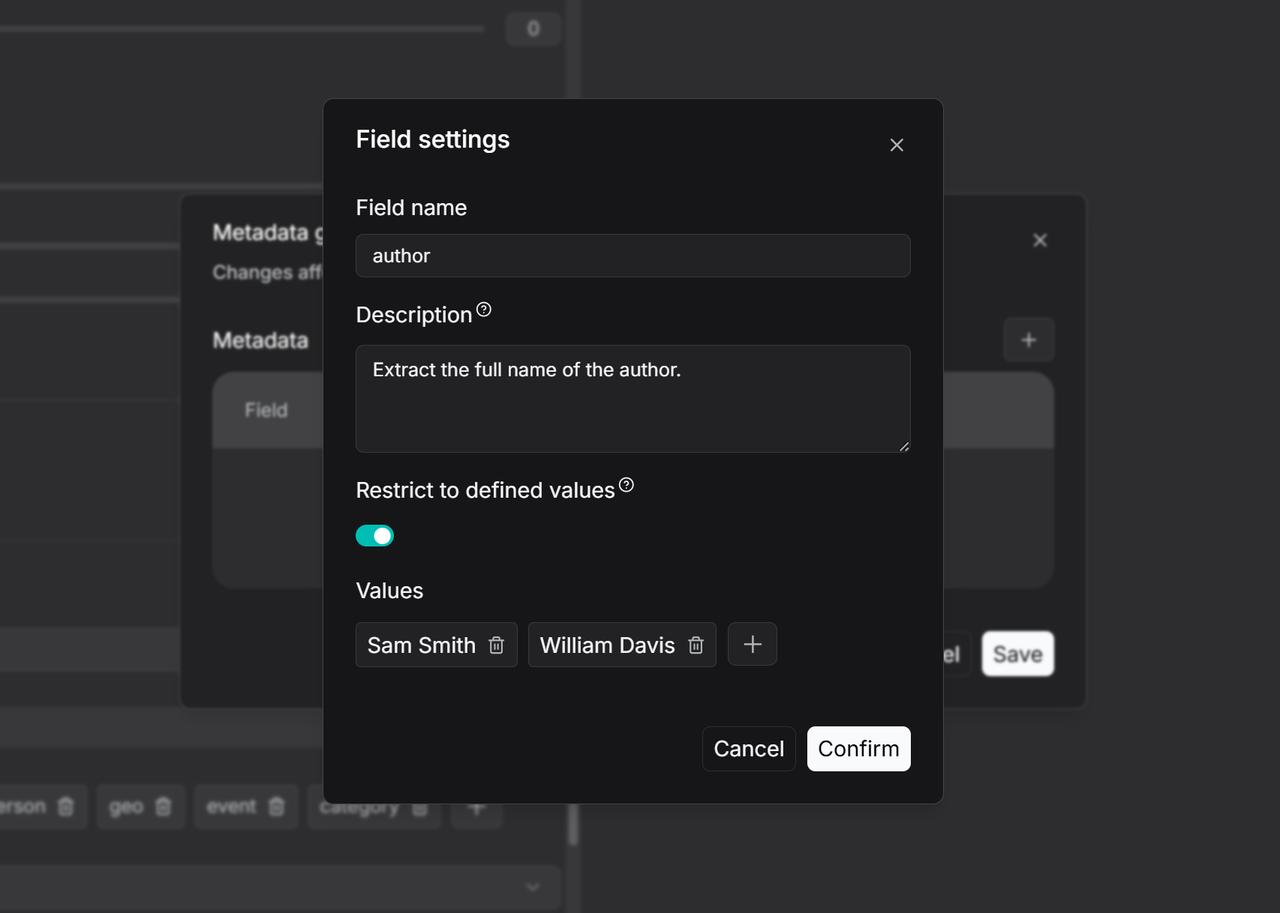
输入字段名称(例如
Author),并在描述部分添加描述和示例。这可以为大语言模型 (LLM) 提供上下文,以便更准确地提取数值。如果留空,LLM 将仅根据字段名称提取数值。 -
要限制大语言模型 (LLM) 仅从预定义列表中生成元数据,请启用 限制为定义的值 (Restrict to defined values) 模式,并手动添加允许的值。之后 LLM 将仅在此预设范围内生成结果。
-
配置完成后,开启 配置 页面上的 自动元数据 (Auto-metadata) 开关。在解析过程中,所有新上传的文件都将应用这些规则。对于已经处理过的文件,你必须重新解析它们以触发元数据的生成。然后,你可以使用过滤功能来检查文件的元数据生成状态。