启用 RAPTOR (Enable RAPTOR)
一种用于长上下文知识检索和摘要的递归抽象方法,在宽泛的语义理解与微观细节之间取得平衡。
RAPTOR (树状组织检索的递归抽象处理) 是 2024 年的一篇论文 中提出的一种增强的文档预处理技术。旨在解决多跳问答 (Multi-hop Question-Answering) 问题,RAPTOR 对文档块 (Chunk) 进行递归聚类和摘要,以构建分层的树状结构。这使得在漫长的文档中能够进行更具上下文感知能力的检索。RAGFlow v0.6.0 集成了 RAPTOR 作为文档聚类的一部分,应用于数据提取和索引之间的数据预处理流水线中,如下图所示。
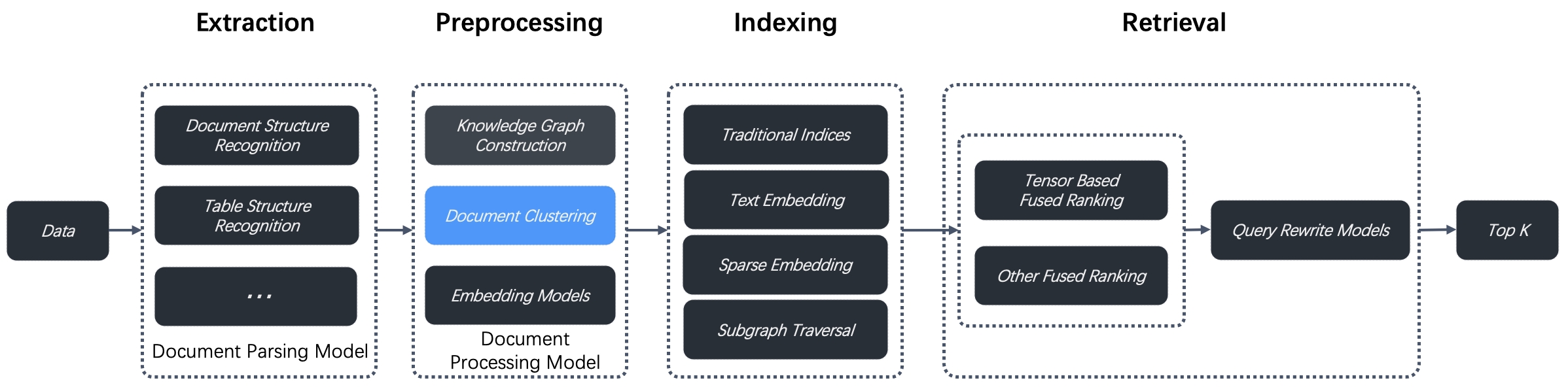
我们对这种新方法的测试表明,在需要复杂、多步骤推理的问答任务上取得了业界领先 (State-of-the-Art, SOTA) 的结果。通过将 RAPTOR 检索与我们内置的分块方法和/或其他检索增强生成 (RAG) 方法相结合,你可以进一步提高你的问答准确率。
启用 RAPTOR 需要大量的内存、计算资源和大语言模型 (LLM) 的 Token。
基本原理 (Basic principles)
在原始文档被划分为文本块 (Chunk) 之后,这些块会根据语义相似度而不是它们在文本中的原始顺序进行聚类。然后,聚类将通过系统的默认聊天模型 (Chat Model) 被总结为更高级别的块。此过程被递归应用,自底向上形成一个包含各个摘要层级的树状结构。如下图所示,初始的块构成叶子节点(显示为蓝色),并被递归总结为一个根节点(显示为橙色)。
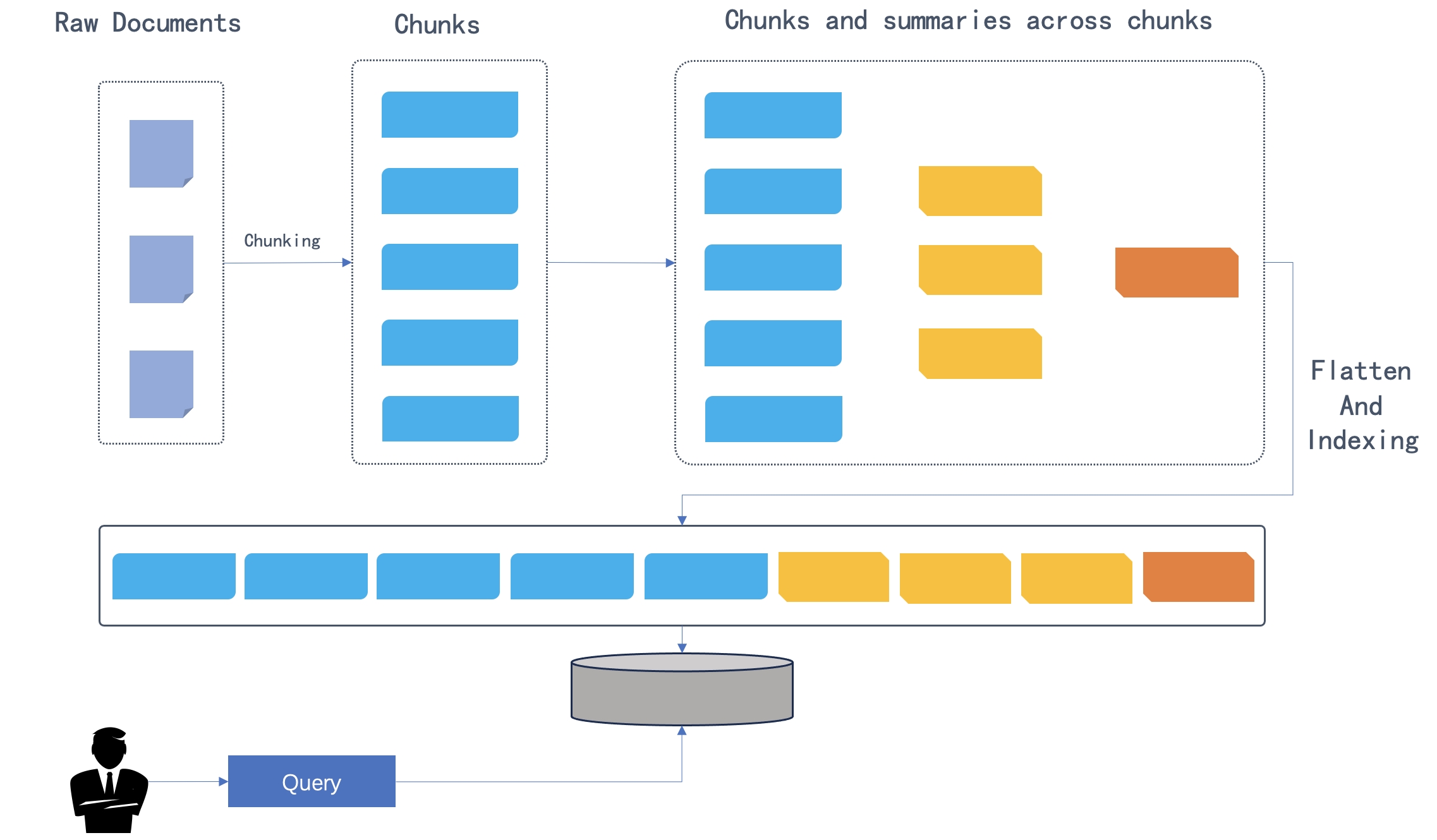
递归聚类和摘要能够捕捉多跳问答所需的宏观理解(通过根节点)和微观细节(通过叶子节点)。
适用场景 (Scenarios)
对于涉及复杂、多步骤推理的多跳问答任务,问题与其答案之间往往存在语义鸿沟。因此,直接使用问题进行检索通常无法找回有助于得出正确答案的相关文本块。RAPTOR 通过为大语言模型 (LLM) 提供更丰富、更具上下文感知和相关性的块来进行摘要,从而在不丢失细粒度细节的情况下实现整体性的理解,从而解决这一挑战。
知识图谱 (Knowledge Graph) 也可以用于多跳问答任务。详情请参阅 构建知识图谱。你可以使用其中一种方法或同时使用两种方法,但请确保你了解其中涉及的内存、计算和 Token 成本。
前提条件 (Prerequisites)
系统的默认聊天模型用于总结聚类内容。在继续之前,请确保你已正确配置了聊天模型 (Chat Model):
参数配置 (Configurations)
RAPTOR 功能默认禁用。要启用它,请在数据集的 配置 (Configuration) 页面上手动开启 使用 RAPTOR 增强检索 (Use RAPTOR to enhance retrieval) 开关。
提示词 (Prompt)
以下提示词将被递归应用于聚类摘要,其中 {cluster_content} 作为内部参数。我们建议你目前保持其原样。该设计将在适当时候进行更新。
Please summarize the following paragraphs... Paragraphs as following:
{cluster_content}
The above is the content you need to summarize.
最大 Token 数 (Max token)
每个生成的摘要块的最大 Token 数量。默认为 256,最大限制为 2048。
相似度阈值 (Threshold)
在 RAPTOR 中,文本块是根据其语义相似度进行聚类的。阈值 (Threshold) 参数设置了将块归为一组所需的最低相似度。
其默认值为 0.1,最大限制为 1。较高的 阈值 (Threshold) 意味着每个聚类中的块较少,而较低的阈值则意味着较多。
最大聚类数 (Max cluster)
要创建的最大聚类数量。默认为 64,最大限制为 1024。
随机种子 (Random seed)
随机种子。点击 + 更改种子值。
快速开始 (Quickstart)
-
导航到数据集的 配置 (Configuration) 页面并更新:
- 提示词 (Prompt):可选 - 建议你在了解其背后的机制之前保持原样。
- 最大 Token 数 (Max token):可选
- 相似度阈值 (Threshold):可选
- 最大聚类数 (Max cluster):可选
-
导航到数据集的 文件 (Files) 页面,点击页面右上角的 生成 (Generate) 按钮,然后从下拉菜单中选择 RAPTOR 以启动 RAPTOR 构建过程。
如果需要,你可以点击下拉菜单中的暂停按钮以中止构建过程。
-
返回 配置 (Configuration) 页面:
当生成 RAPTOR 分层树状结构后,RAPTOR 字段将从
未生成 (Not generated)变更为已在特定时间戳生成 (Generated at a specific timestamp)。你可以通过点击该字段右侧的垃圾桶按钮来删除它。 -
一旦生成了 RAPTOR 分层树状结构,你的聊天助手和 检索 (Retrieval) 智能体 (Agent) 组件将默认使用它进行检索。