数据解析入库流水线快速上手 (Ingestion Pipeline Quickstart)
RAGFlow 的数据解析入库流水线 (Ingestion Pipeline) 是一个可定制的、逐步进行的工作流,为您的文档实现高质量 AI 检索和回答做好准备。您可以将其视为积木:通过连接不同的处理“组件 (Components)”,构建一条量身定制的、符合您特定文档和需求的流水线。
RAGFlow 是一个开源的 RAG 平台,具备强大的文档处理能力。其内置模块 DeepDoc 使用智能解析对文档进行分块,以实现精确检索。为了应对现实世界中的多样化需求(例如多样的文件来源、复杂的排版布局以及更丰富的语义),RAGFlow 现推出了数据解析入库流水线 (Ingestion Pipeline)。
数据解析入库流水线允许您自定义文档处理的每一个步骤:
- 针对不同场景应用不同的解析和分块 (Chunking) 规则
- 添加诸如摘要生成或关键词提取之类的预处理操作
- 连接到云端网盘和在线数据源
- 针对表格和混合内容使用先进的布局感知模型
这种灵活的流水线能够自适应您的数据,从而提高 RAG 中的回答质量。
1. 了解流水线的核心组件 (Core Pipeline Components)
- Parser (解析器) 组件:读取并理解您的文件(PDF、图像、电子邮件等),提取文本和结构。
- Transformer (转换器) 组件:通过利用 AI 添加摘要、关键词或问题,来增强文本并提升检索效果。
- Chunker (分块器) 组件:将长文本分割成大小最佳的片段(“分块/块”),以便实现更好的 AI 检索。
- Indexer (索引器) 组件:最后一步。将处理后的数据发送到文档引擎(支持混合全文检索和向量检索)。
2. 创建数据解析入库流水线
- 进入 Agent 页面。
- 点击 Create agent,并从空白画布或预构建模板开始(建议初学者使用模板)。
- 在画布上,从右侧面板拖动并连接组件来设计您的流程(例如:Parser → Chunker → Transformer → Indexer)。
现在让我们来构建一条典型的数据解析入库流水线!
3. 配置 Parser (解析器) 组件
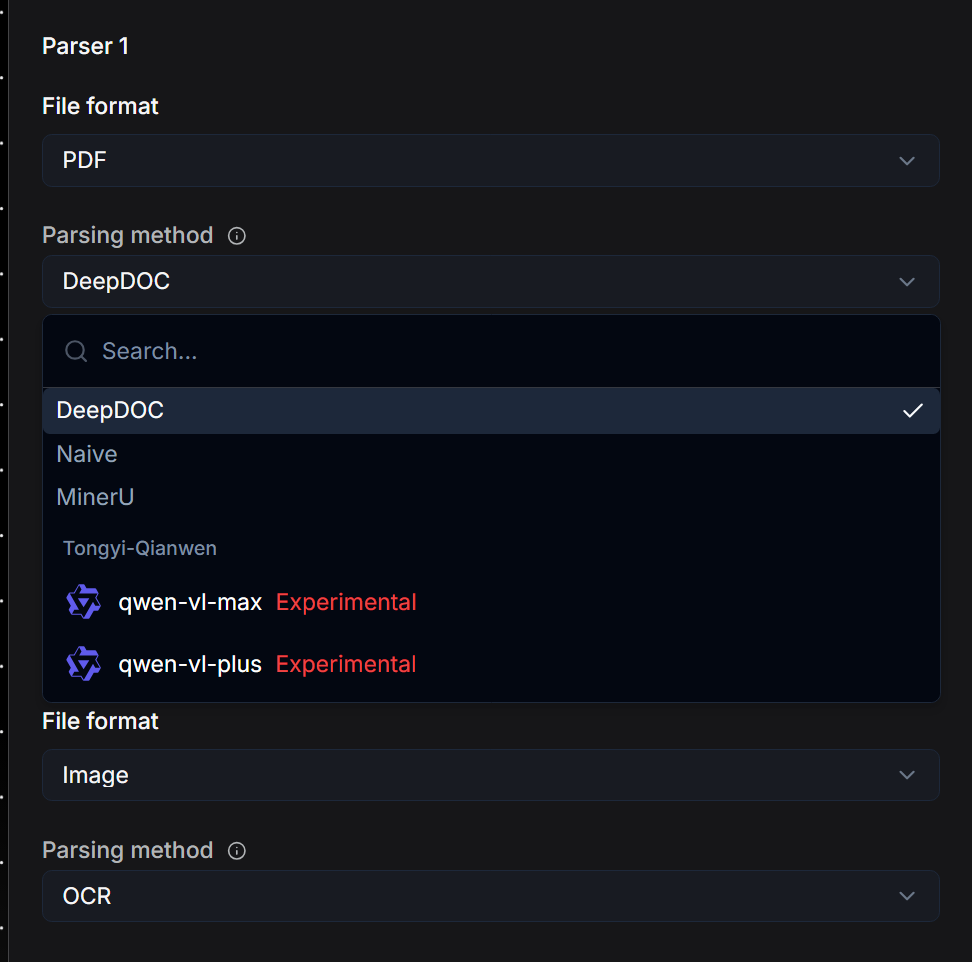
Parser 组件可将您的文件转换为结构化文本,同时保留布局、表格、标题和其他格式。它支持 8 个大类、23 种以上的文件格式,包括 PDF、图片 (Image)、音频 (Audio)、视频 (Video)、电子邮件 (Email)、电子表格 (Spreadsheet / Excel)、Word、PPT、HTML 和 Markdown。以下是一些关键配置:
- 对于 PDF 文件,选择以下选项之一:
- DeepDoc(默认):RAGFlow 内置的模型。最适合扫描文档或包含表格的复杂布局。
- MinerU:行业领先,适用于处理复杂的元素(如数学公式)和错综复杂的布局。
- Naive:简单的文本提取。适用于排版干净、不含复杂元素的文本型 PDF。
- 对于图片文件:默认使用 OCR。您也可以配置多模态大模型 (Vision Language Models, VLMs) 进行高级视觉理解。
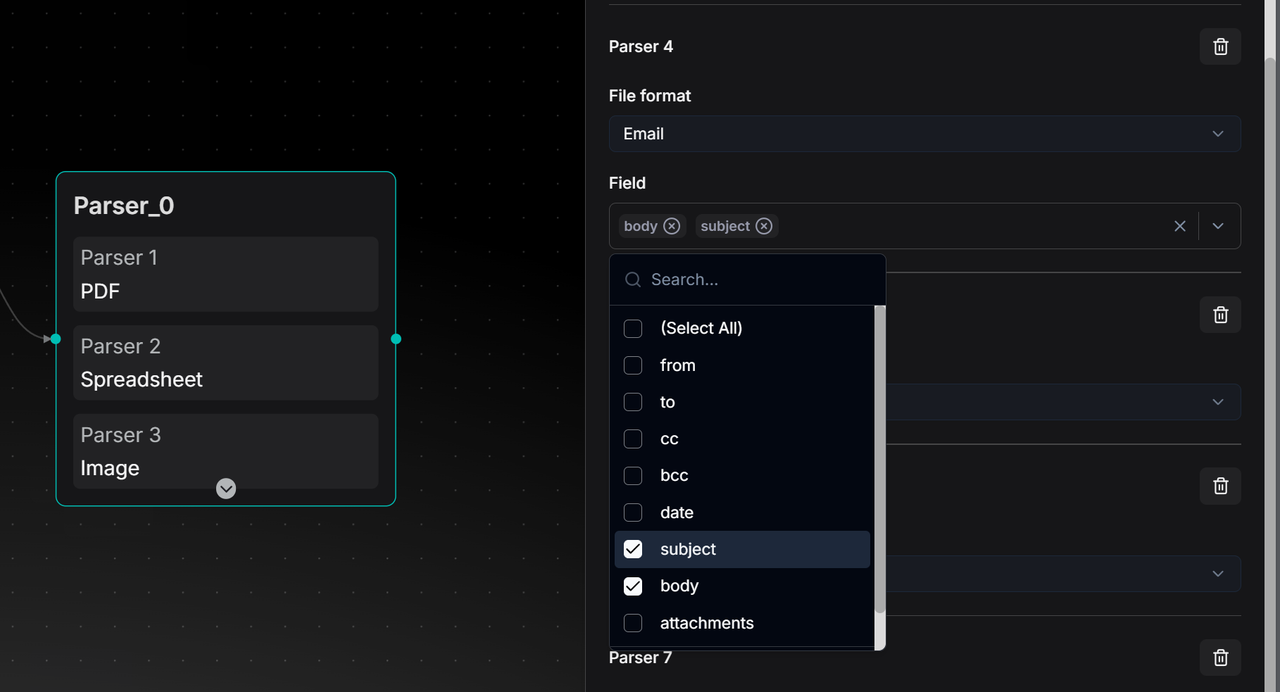
- 对于电子邮件文件:选择要解析的特定字段(例如 "subject" 主题、"body" 正文)以实现精准提取。
- 对于电子表格:输出为 HTML 格式,保留行/列结构。
- 对于 Word/PPT:输出为 JSON 格式,保留文档层级结构(标题、段落、幻灯片)。
- 对于纯文本和标记语言 (HTML/MD):自动剥离格式标记,输出干净的纯文本。
4. 配置 Chunker (分块器) 组件
Chunker 组件能够智能地对文本进行分块。其目标是防止大语言模型 (LLM) 的上下文窗口 (Context Window) 溢出,并提高混合检索 (Hybrid Search) 中的语义准确性。有两种核心分块方法(可以按顺序组合使用):
- By Tokens (按 Token 分块)(默认):
- Chunk Size (分块大小):默认值为 512 个 token。在检索质量和模型兼容性之间取得平衡。
- Overlap (重叠度):设置 Overlapped percent (重叠百分比),将前一个分块的结尾复制到下一个分块的开头。从而提高语义连贯性。
- Separators (分隔符):默认使用
\n(换行符)优先在自然的段落边界进行划分,避免在句子中间断开。
- By Title (按标题分块)(层级分块):
- 最适合结构化文档,如手册、论文、法律合同。
- 系统根据章节结构对文档进行切分。每个分块代表一个完整的结构单元。
在当前的设计中,如果同时使用 Token 和 Title 方法,请先连接 Token chunker 组件,然后再连接 Title chunker 组件。如果直接将 Title chunker 连接到 Parser,可能会导致电子邮件、图片、电子表格和文本文件出现格式错误。
5. 配置 Transformer (转换器) 组件
Transformer 组件旨在消除“语义鸿沟”。通常而言,它使用 AI 模型来添加语义元数据,使您的内容在检索过程中更容易被发现。它包含四种生成类型:
- Summary (摘要):生成简明扼要的概述。
- Keywords (关键词):提取关键术语。
- Questions (问题生成):生成该文本块可以回答的问题。
- Metadata (元数据):自定义元数据提取。
如果您有多个 Transformer,请确保为每个功能独立设置 Transformer 组件(例如:一个用于生成摘要,另一个用于提取关键词)。
以下是一些关键配置:
- Model modes (模型模式):(选择其一)
- Improvise (即兴):更具创造性,适合用于问题生成。
- Precise (精准):严格忠实于原文,适合用于摘要生成或关键词提取。
- Balance (平衡):折中方案,适用于大多数场景。
- Prompt engineering (提示词工程):每种生成类型的系统提示词 (System Prompt) 都是开放的,可进行自定义。
- Connection (连接关系):Transformer 可以连接在 Parser 之后(处理整个文档),也可以连接在 Chunker 之后(处理每一个分块)。
- Variable referencing (变量引用):该节点不会自动获取内容。在用户提示词 (User Prompt) 中,需要手动输入
/并选择具体的上游输出变量来引用它们(例如/{Parser.output}或/{Chunker.output})。 - Series connection (串联连接):当链式连接多个 Transformer 时,如果变量引用正确,第二个 Transformer 组件将处理第一个组件的输出(例如基于摘要生成关键词)。
![]()
![]()
![]()
6. 配置 Indexer (索引器) 组件
Indexer 组件进行索引构建以实现最优检索。它是将处理后的数据写入搜索引擎(如 Infinity、Elasticsearch、OpenSearch)的最后一步。以下是一些关键配置:
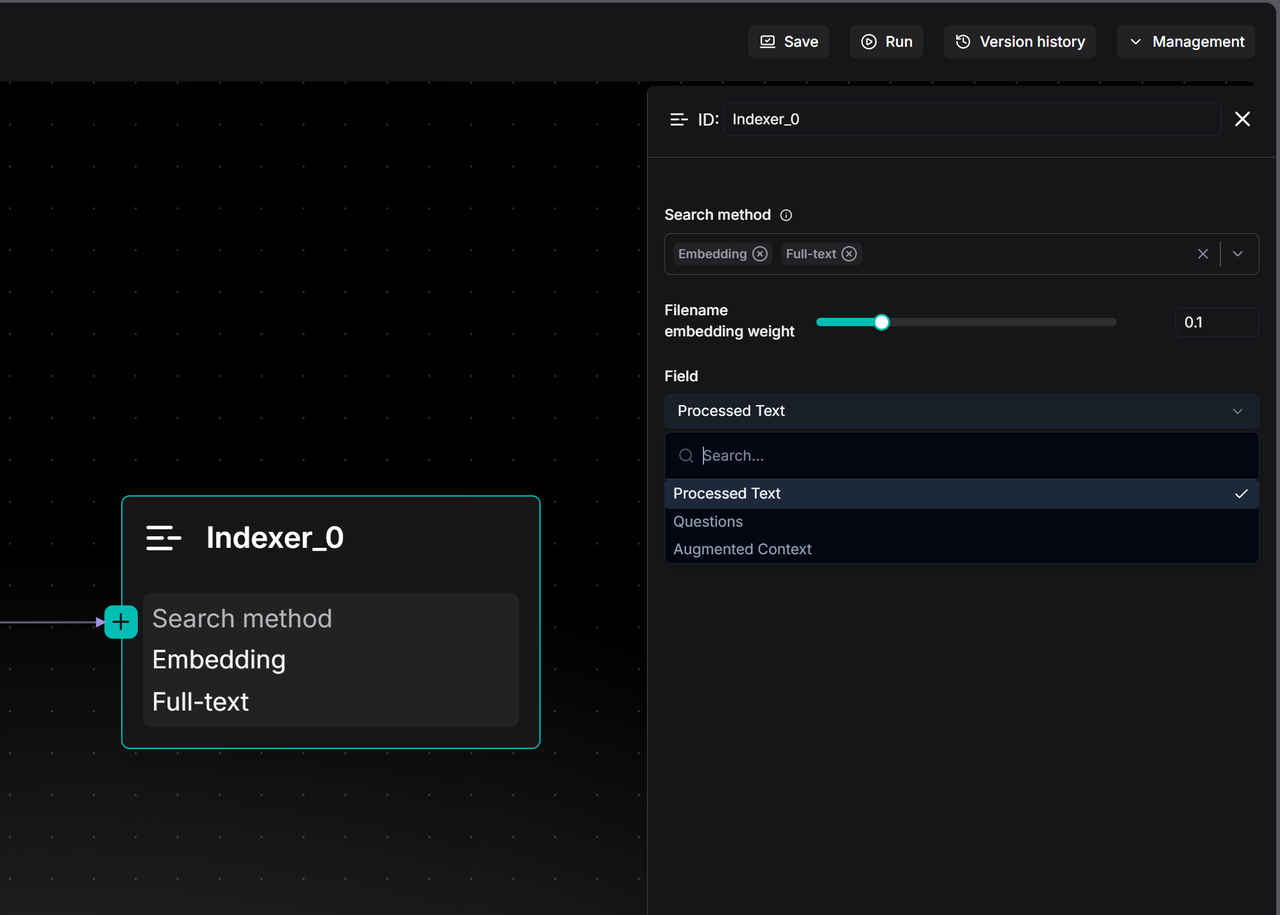
- Search methods (检索方法):
- Full-text (全文检索):用于精确匹配(代码、名称等)的关键词检索。
- Embedding (向量检索):使用向量相似度进行语义搜索。
- Hybrid (混合检索,推荐):结合这两种方法以获得最佳召回率。
- Retrieval Strategy (检索策略):
- Processed text (处理后的文本)(默认):对分块文本进行索引。
- Questions (问题):对生成的问题进行索引。与“文本-文本”相比,通常能产生更高的相似度匹配。
- Augmented context (增强上下文):对摘要而不是原始文本进行索引。适合宽泛的主题匹配。
- Filename weight (文件名权重):通过滑块控制将文档文件名作为检索时的语义信息包含在内。
- Embedding model (嵌入模型):自动使用在创建数据集 (Dataset) 时设置的模型。
要同时检索多个数据集,所有选定的数据集必须使用相同的嵌入模型 (Embedding Model)。
7. 测试运行 (Test Run)
在流水线画布上点击 Run(运行)上传示例文件,以查看逐步运行的结果。
8. 将流水线连接到数据集
- 在创建或编辑数据集时,找到 Ingestion pipeline(数据解析入库流水线)区域。
- 点击 Choose pipeline(选择流水线)并选择您保存的流水线。
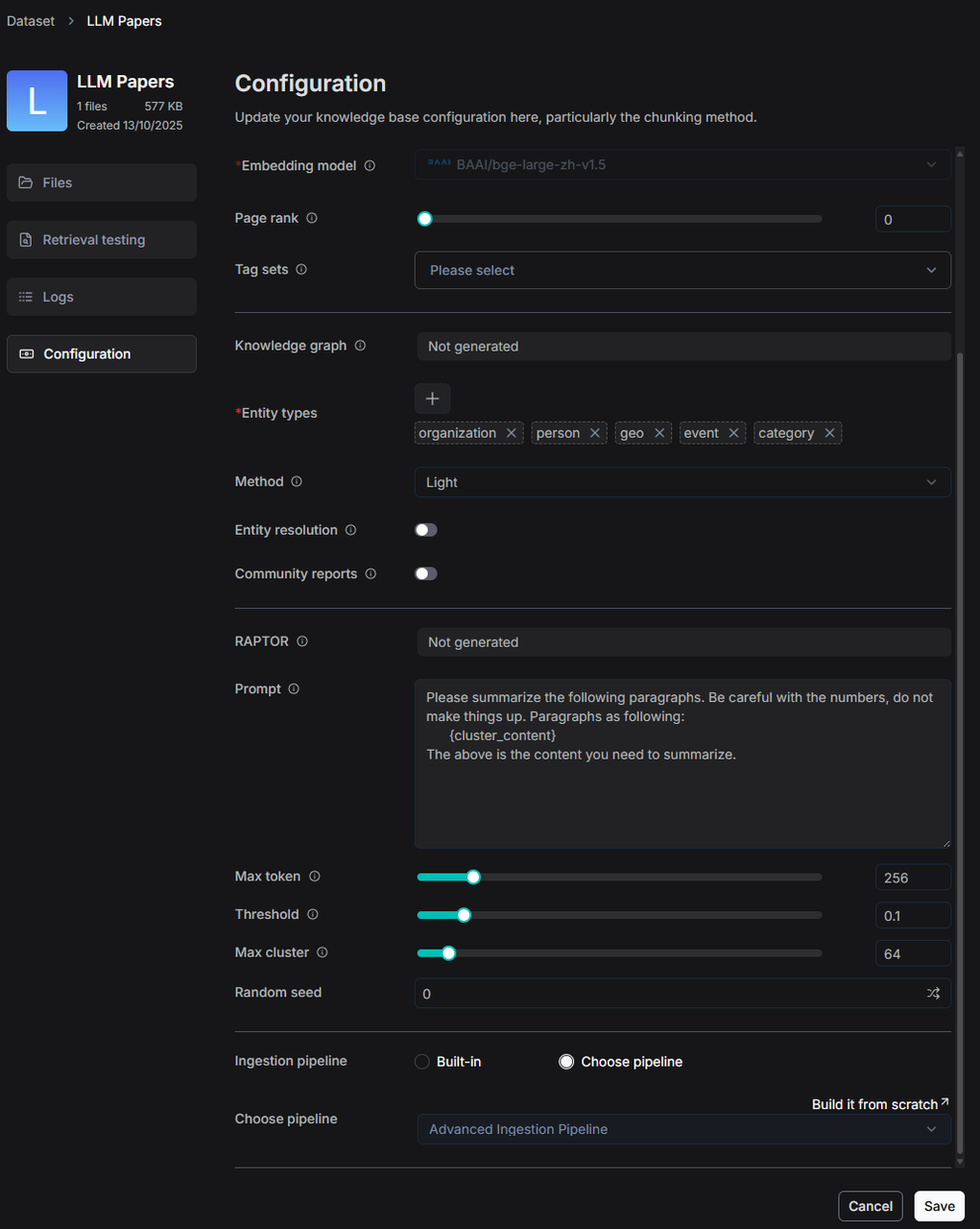
现在,上传到该数据集的任何文件都将由您的自定义流水线进行处理。